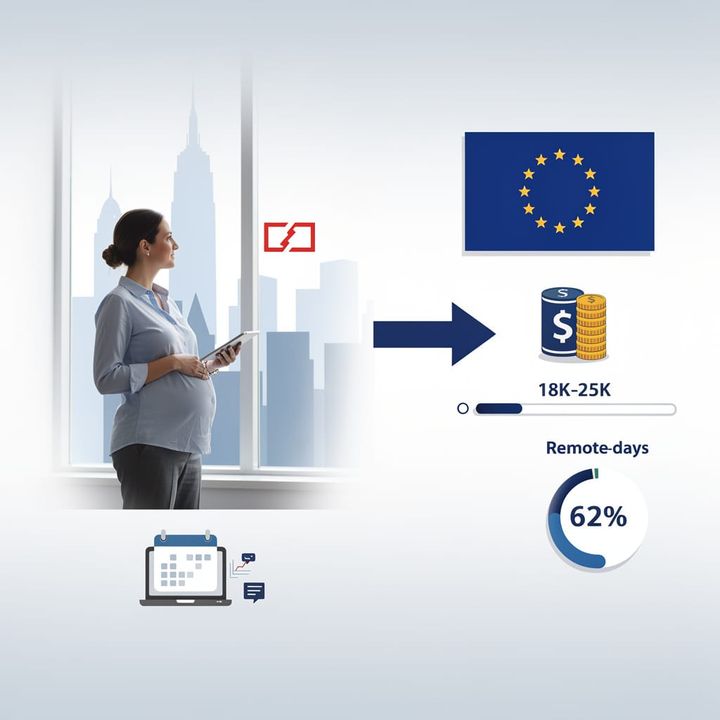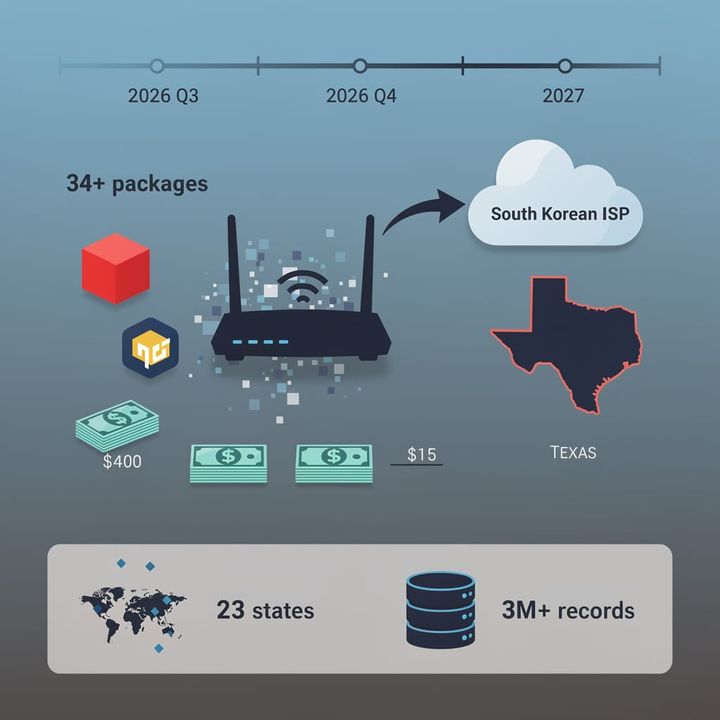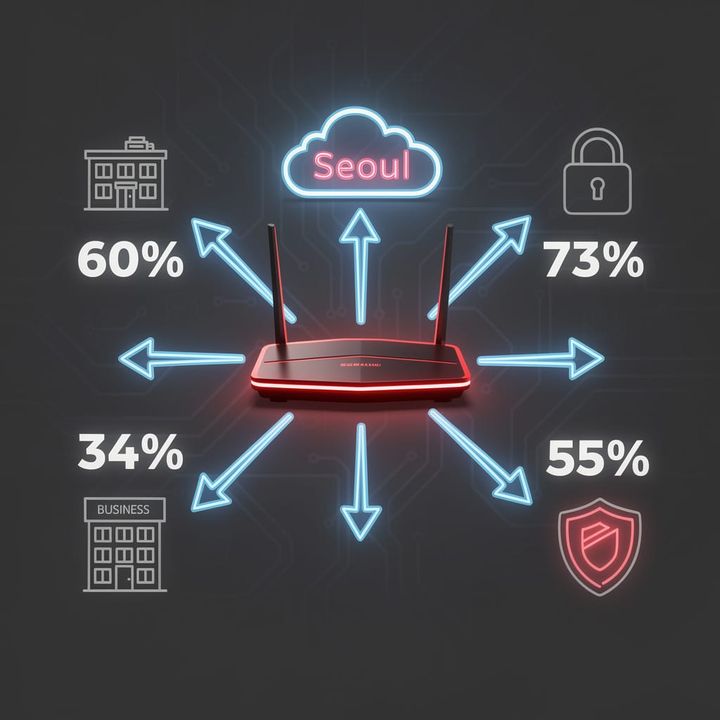
$49 Router, $25K Breach: SMBs Selling Data to Seoul via Unpatched Gateways
🔥 The $49.99 Router That's Selling Your Business to South Korea
Your $49 Best Buy router has 8-year-old unfixed CVEs and zero hardware encryption — meanwhile some crew in Ulsan is hauling your VPN traffic through Seoul cloud nodes while your Houston ISP shrugs 🔥 Hotel Wi-Fi