AI Gets Memory; Consumers Get Shortage: Micron-Anthropic Deal Exposes DRAM Allocation Crisis
TL;DR
- 80–90% DRAM Spike Is Just the Beginning—Industry's Recovery Narrative Won't Hold. With AI compute locking up memory supply and manufacturers prioritizing AI contracts over general market, what stops DRAM prices from climbing through 2028?
- Serverless HPC: 50% TCO Savings vs. Ephemeral Security Gaps. Does serverless GPU compute's 50% cost advantage outweigh the credential management risks for your workload?
💾 The Memory Bottleneck Nobody Wants to Acknowledge
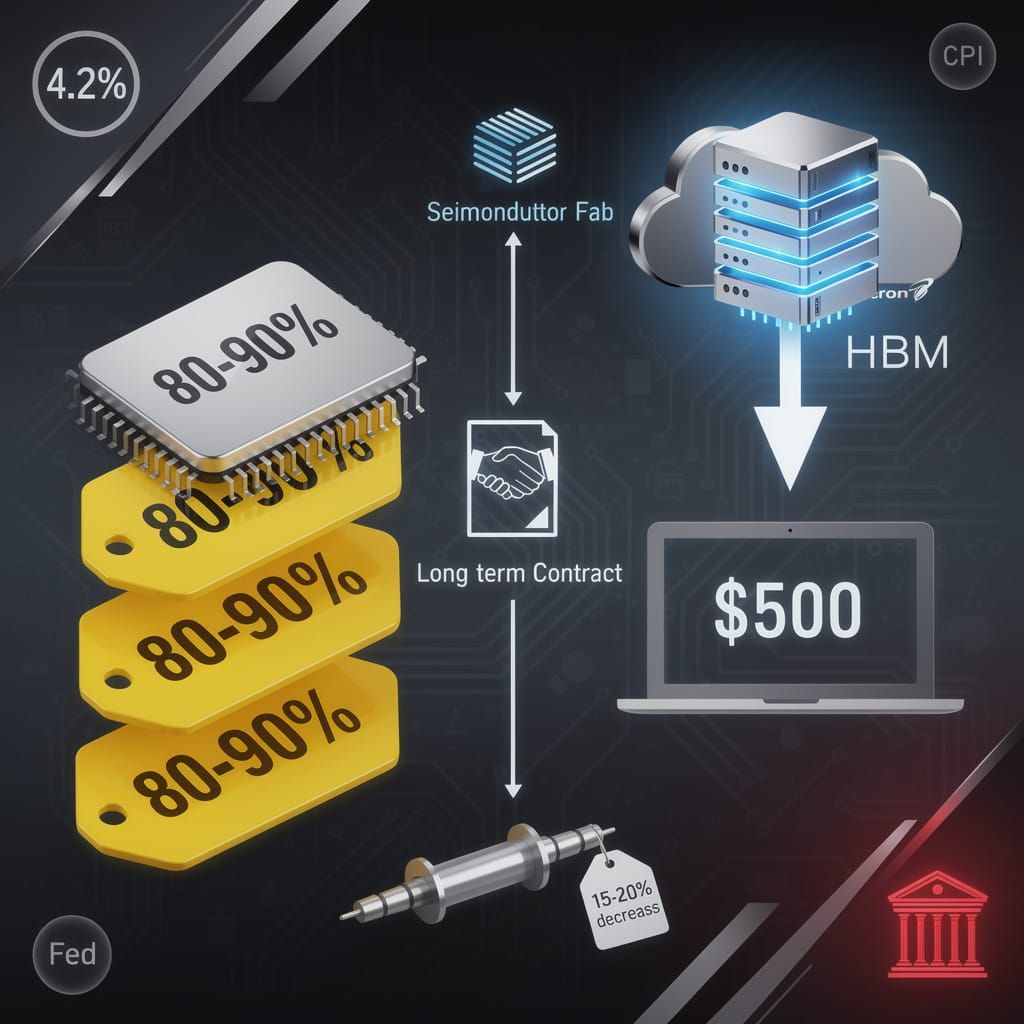
DRAM prices spiked 80–90% and Apple raised MacBook prices up to $500—yet the industry insists "gradual catch-up before year-end." It's not coming. AI compute demands lock Micron's HBM capacity. Long-term contracts hold half supply hostage. China's expansion delays until 2028. New fab output adds just 15–20%—nowhere near enough. The Micron–Anthropic deal ("strategic alliance") confirms the allocation: AI infrastructure gets memory. General market gets shortage. If manufacturers won't invest in capacity—where does relief come from? 💾⚠️
Apple's Lock-In Meets the DRAM Supply Crunch
The June 2026 memory market disruption did not arrive as a surprise. Micron's inability to invest in capital expenditure—a gap the company's own CEO attributed to "declining margins and aggressive customer pricing"—represents a failure years in the making. Industry observers should view the 80–90% DRAM price spike not as an anomalous market correction, but as the predictable outcome of sustained underinvestment.
Apple's June 25 announcement of 10–20% price hikes across MacBooks, iPads, and HomePods—with select items exceeding 50%—illustrates where the pressure lands. The increases extend to MacBooks rising by up to $500, iPads by $200, Apple TV by 54%, and the MacBook Neo surging 17% to $699. Tim Cook acknowledged the increases as unavoidable given supplier memory and storage costs projected to linger beyond 2027. Apple's base M6 chip delivers up to 200 GB/s memory bandwidth, a 31% improvement over M5's 153 GB/s, but the architecture deliberately prevents independent upgrades. Apple's gross margin has dropped to 39%, and stock AAPL fell 6% on the pricing move. Notably, Apple maintained iPhone 17 pricing unchanged—strategic inventory management ahead of the September iPhone 18 launch, where analysts project starting prices of $1,299 or higher. Consumers now face elevated memory costs with zero flexibility to mitigate expenses through after-market expansion.
Questioning the Recovery Narrative
The industry projects "gradual catch-up possible before year-end." This forecast lacks substantiation. The June 28 analyst briefings document projected 40–50% quarter-over-quarter price increases in Q3 and 30–40% in Q4. Long-term contracts covering half capacity limit new supply; Chinese DRAM/NAND expansion remains delayed until 2028. Micron's U.S. Fab completions remain delayed, and legacy production lines continue their decline.
The Micron-Anthropic strategic alliance announced June 22-23 underscores where manufacturing priorities actually land. Micron committed to multi-year supply agreements providing HBM, DRAM, and SSDs to Anthropic while simultaneously investing in the AI company's $65 billion Series H funding round at a $965 billion valuation. Samsung and SK hynix participated alongside Micron. This deal directly removes memory capacity from the general market—it secures Anthropic's infrastructure requirements and locks Micron into AI-focused production. The partnership enables Anthropic to deploy Claude models at scale using Micron hardware, accelerating AI infrastructure innovation while tightening general-market supply. AI compute demand remains the dominant driver reshaping semiconductor manufacturing priorities, and this alliance confirms it.
On the macroeconomic side, Fed Chair Kevin Warsh's May 31 shift toward inflation perception-based policy signals prolonged high rates. CPI accelerated to 4.2% by June 10, driven partly by energy spikes from the Strait of Hormuz blockade. The combination of sustained inflation, elevated interest rates, and geopolitical supply disruptions creates a compounding effect on component pricing—input costs remain elevated across the supply chain, reducing manufacturers' ability to absorb memory price increases. Tech mega-caps including Alphabet (-6%) and Amazon (-4%) sold off June 26 as AI capex anxiety intensified, reflecting market unease about whether infrastructure investments justify themselves amid cost pressures.
The market's reaction to Micron's June 24 earnings beat ($33.5B revenue, ~81% gross margin) reveals a distorted picture: the company reached $1 trillion market valuation while supply constraints intensify. Citi lifted Micron's price target to $840, but investor confidence masks a supply crisis that financial performance cannot resolve.
Structural Vulnerabilities Persist
The signals indicate a medium-impact disruption that reveals deeper systemic fragility:
- Supply imbalance: AI compute requirements redirect manufacturing resources from DRAM to HBM, and no near-term reversal addresses this. Micron and Anthropic's June 26 strategic alliance confirms the priority shift—Anthropic secured long-term memory commitments while general market availability shrinks.
- Investment deficit: Long-term contracts and delayed Chinese expansion lock in constrained conditions through 2028, with new fab output adding only 15–20% supply—insufficient to offset demand.
- Macroeconomic compounding: Fed policy signals sustained high rates through 2027 (Kevin Warsh's May 31 address); CPI at 4.2% with energy-driven inflation; Treasury issuance reaching all-time highs; K-shaped recovery signals rising inequality. These factors elevate baseline input costs across manufacturing, reducing relief from any individual memory price correction.
- Consumer exposure: Premium platforms absorb cost increases with no upgrade pathway. Apple seeks Chinese supplier CXMT despite rising prices, signaling supply-chain desperation. Apple maintained iPhone pricing ahead of September launches—a tactical move to move existing inventory before iPhone 18 resets price expectations upward.
- Pricing escalation: Analyst forecasts show 40–50% QoQ increases in H3 and H4 2026, followed by YoY gains in 2027; shortages persist through 2028. Inflation signals suggest these pressures will not ease from the demand side.
The industry framing presents these constraints as temporary market dynamics. The evidence supports a different conclusion: the memory ecosystem built its current bottleneck through deliberate optimization for short-term margins, and resolution requires capital commitments that remain conspicuously absent from the announced roadmap. The Micron-Anthropic deal demonstrates where investment flows—toward AI infrastructure, not general-market DRAM relief.
💰 The Serverless HPC Promise: Runpod's Bold Bet on Ephemeral GPU Workloads
50.3% lower total cost of ownership. Runpod's serverless GPU model beats on-prem clusters: $122K vs $247K over 3 years, 95% immediate ROI. But ephemeral workers create credential surfaces traditional monitoring can't track—and security teams are right to be skeptical. For whom is this actually a win? 🚀
Is Ephemeral Compute the Future, or a Security Liability?
Runpod's June 2026 launch of its serverless endpoint enters a crowded market with a specific pitch: developers can now deploy AI model serving workflows through GitHub-triggered builds into GPU-accelerated containers, paying only for execution time. The platform targets sub-second response latencies and positions itself as a direct challenger to always-on GPU clusters, particularly for startups and smaller engineering teams.
The timing aligns with a broader inflection point. On May 12, 2026, Meta's release of Llama 3.1 405B—and Runpod's immediate serverless deployment of Llama 3.1 8B with vLLM—demonstrated that the platform can handle frontier-class workloads without infrastructure commitments. Runpod simultaneously secured $20 million in funding from Intel Capital and Dell Technologies Capital, signaling investor conviction in serverless GPU economics. Yet the security implications of ephemeral GPU workers warrant continued scrutiny.
The June 25, 2026 launch of Runpod's serverless inference platform—targeting 750K+ developers across 31 regions—provides concrete evidence of the platform's scale ambitions. The service introduced Multi-Instance GPU (MIG) technology, enabling dynamic allocation of GPU slices to reduce waste and improve utilization. Cold-start latency, a persistent concern for serverless architectures, is mitigated through FlashBoot and model caching mechanisms. These technical mitigations address the cold-start vulnerability, but they do not eliminate the underlying credential management challenge. Each container spawns with a potentially unique credential surface, and the short-lived nature of these workers complicates traditional monitoring and incident response frameworks.
The security landscape adds regulatory weight to these concerns. On June 2, 2026, the U.S. government issued an executive order requiring AI firms to share frontier models 30 days before public release, increasing compliance burden and cybersecurity risk. Separately, Anthropic delayed the Claude Mythos launch on April 26, 2026, citing identified security vulnerabilities—a reminder that AI product readiness and infrastructure security remain coupled risks. Runpod acknowledges the credential rotation gap, recommending short-lived credential rotation policies—but implementing consistent rotation across dynamic, auto-scaling environments requires maturity many smaller teams lack. The June 2026 launch expanded capacity globally, including deployment in AP-IN-1, but the operational governance frameworks remain nascent for teams without dedicated security expertise.
Measuring Real Impact: Cost Savings vs. Operational Complexity
The claimed cost benefits demand contextual examination—and concrete data now exists to validate them.
In June 2026, researcher James Sandy presented a comparative study demonstrating that cloud GPU platforms like Runpod deliver 50.3% lower total cost of ownership than on-premises GPU clusters over three years for machine learning workloads. Using four NVIDIA A100 units, the cloud solution achieved $122,000 in total expense versus $247,000 for equivalent on-premises infrastructure. The mechanism is straightforward: cloud eliminates fixed capital expenditure (approximately $60,000 in hardware procurement), ongoing maintenance, and power/cooling costs, replacing them with pay-per-use billing. Sandy reported immediate ROI of approximately 95%.
Contextualizing the break-even analysis:
- Hardware capex avoidance: Single 4xA100 node requires $60,000+ upfront investment before operational costs
- Operational flexibility: Cloud solutions enable deployment in hours versus procurement cycles spanning months
- Scaling economics: Variable billing aligns costs to actual utilization rather than peak capacity provisioning
- GPU availability: Runpod's June 2026 deployment of H100 80GB HBM3 capacity across 31 regions addresses the hardware scarcity that drove enterprise GPU costs in 2024–2025, when NVIDIA's RTX Pro 6000 Blackwell traded at significant premiums on secondary markets
However, organizations must account for potential egress costs and integration complexity. The EU Data Act's impact on cross-border data flows, effective 2027, introduces regulatory considerations that may alter cost calculations for European deployments.
Serverless architectures also introduce variable latencies due to cold-start overhead—a critical consideration for production AI serving where P99 latency directly impacts user experience. Runpod's FlashBoot technology directly addresses this challenge for inference workloads, enabling faster container initialization. Optimization tools like Profile (which demonstrated 15x throughput increases and 93% cost reduction on Qwen3.6-27B) suggest operational complexity remains a factor; teams must invest in tuning to extract maximum efficiency from cloud GPU infrastructure.
Who Actually Benefits?
Strong beneficiaries:
- Early-stage startups with fluctuating compute needs and limited DevOps capacity, avoiding $60,000+ hardware commitments
- Research teams requiring intermittent GPU access without infrastructure procurement cycles
- Organizations transitioning from on-premises GPU clusters seeking immediate cost relief and capital preservation
- Developers requiring rapid model deployment without infrastructure management overhead
Less compelling for:
- Production systems requiring consistent sub-100ms response times without cold-start mitigation strategies
- Organizations with predictable, continuously utilized GPU workloads where reserved instances may outperform pay-per-invocation pricing
- Enterprises subject to compliance requirements around workload isolation and audit logging that require mature container security governance
- Regulated industries where the June 2026 executive order requiring 30-day model-sharing disclosures imposes additional compliance layers on ephemeral infrastructure
What This Signals for Cloud HPC Adoption
Runpod's launch indicates accelerating fragmentation in HPC cloud strategy, not convergence. Hyperscalers offer managed GPU instances with robust tooling but limited elasticity; pure serverless platforms trade predictability for flexibility. The market increasingly bifurcates between teams willing to accept operational complexity for cost optimization and those prioritizing reliability.
Hardware cost pressures reinforce this bifurcation. NVIDIA's RTX Pro 6000 Blackwell entered the enterprise retail market at $8,435–$8,565 in March 2025, then fell to a preorder low of $7,673 before NVIDIA listed the card at $13,250 on its marketplace in September 2025—creating a $5,600 gap that signals pricing power consolidation among chipmakers. AMD and Intel's June 2026 announcement of a unified CE API for AI compute stack suggests the GPU vendor landscape is evolving toward interoperability, potentially easing hardware lock-in concerns. For organizations evaluating GPU infrastructure, these hardware cost trajectories suggest on-premises capital decisions carry increasing uncertainty.
Runpod projects acceleration in startup migration toward pay-as-you-go execution environments through 2027. The Sandy study, combined with Meta's open-source LLM releases driving increased serverless adoption, suggests this projection has structural support rather than mere vendor optimism. The platform's expansion to 31 regions and per-second billing model addresses geographic and cost predictability concerns that previously limited adoption. Whether enterprise adoption follows depends on resolving the security and latency trade-offs that currently limit deployments in regulated industries.
The platform succeeds as a specialized tool for specific use cases—particularly rapid prototyping and capital-constrained AI development—rather than a wholesale replacement for dedicated GPU infrastructure. Infrastructure decision-makers should evaluate serverless GPU compute against workload-specific latency requirements, security maturity, and total cost of ownership rather than adopting based on cost narratives alone. The 50.3% TCO advantage is real, but it accrues fully only when organizations have the operational capacity to manage ephemeral infrastructure responsibly.

Comments ()