2.198 Exaflops: LineShine Supercomputer in China Claims Global Leadership via CPU-Only Architecture
TL;DR
- 2.198 Exaflops: China's LineShine Reclaims Global Supercomputing Lead via CPU-Centric Architecture. Can a CPU-only architecture truly outperform GPU-scaling in the race for exascale dominance?
- 100x Performance Boost: Intel 8087 Coprocessor Shifts Precision Computing in 2026. How does the Intel 8087's 100-fold reduction in compute cycles impact the future of scientific computing?
- 30% Reduction in Quantum Simulation Runtime: Hybrid Architectures Drive Industrial Utility. How does a 30% reduction in quantum simulation runtime impact the timeline for industrial R&D adoption?
⚡️ The CPU Resurgence: LineShine Reclaims Exascale Leadership
2.198 exaflops! A staggering leap that dwarfs previous peaks, equivalent to millions of GPUs working in unison ⚡️ LineShine's CPU-only architecture breaks US dominance. But is raw power worth a 42.2 MW energy drain? China's new crown—will your local grid handle this scale?
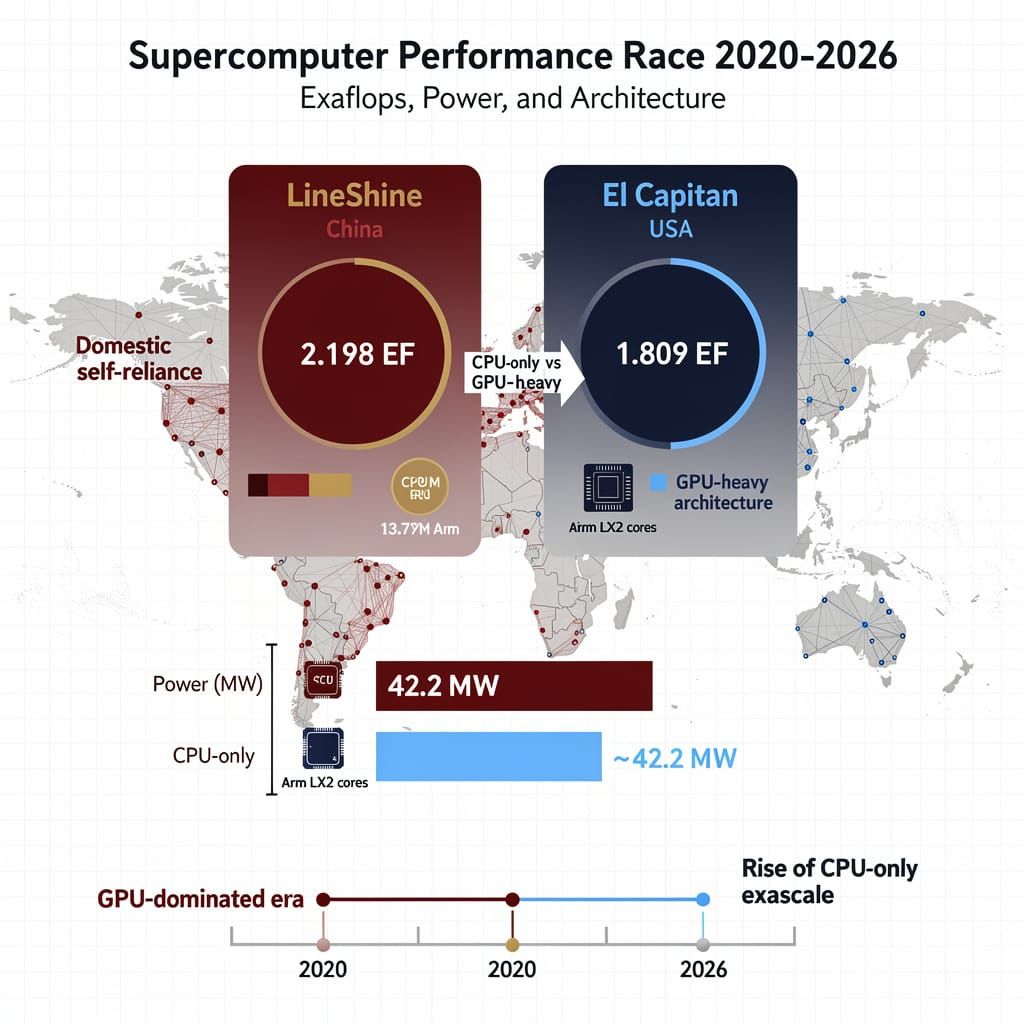
On June 23, 2026, the National Supercomputing Centre in Shenzhen announced that its LineShine supercomputer achieved a sustained double-precision performance of 2.198 exaflops. Unveiled at ISC 2026 in Hamburg, this milestone establishes LineShine as the world's most powerful system, surpassing the US-based El Capitan, which maintains a score of 1.809 exaflops. This represents the first time a Chinese system has held the top rank since 2017.
Architectural Pivot: Domestic Self-Reliance
LineShine demonstrates a strategic shift away from GPU-centric scaling. The system utilizes 13.79 million cores based on domestically produced 304-core Arm-based LX2 chips. By leveraging the ARMv9 architecture and proprietary LingQi interconnects, the system bypasses reliance on American semiconductor exports and operates as a high-performance CPU-only environment.
This configuration enables high throughput for traditional scientific computing and FP64 tasks. However, it ranks fourth on the HPL-MxP benchmark, indicating limitations in mixed-precision acceleration compared to GPU-heavy systems. The deployment of 42.2 MW of power for 52 GFW highlights a critical duality: while the CPU-centric approach targets specific workload efficiency, the total energy draw remains a significant infrastructure challenge.
Timeline of Exascale Evolution
- 2020–2023: US dominance via GPU scaling; El Capitan leads at 1.809 exaflops.
- June 2026: LineShine reaches 2.198 exaflops, marking China's return to the TOP500 peak.
- Late 2027: Projected expansion of AI-centric semiconductor ecosystems and hybrid cloud scaling.
Strategic Impacts
The success of the LX2 chip and LingQi interconnect demonstrates a viable path toward national computing sovereignty, creating a causal chain that pressures global semiconductor strategies.
Geopolitical: Domestic chip success $\rightarrow$ reduced reliance on U.S.-controlled technology. Infrastructure: Focus on high-core counts $\rightarrow$ increased demand for local energy and liquid cooling. Scientific: High FP64 throughput $\rightarrow$ accelerated energy-intensive scientific simulations. Environmental: 42.2 MW power draw $\rightarrow$ heightened focus on sustainable data center policy.
This breakthrough indicates a fragmented global HPC landscape. While the US leads in specialized acceleration—evidenced by Nvidia's RTX Spark and Intel's Xeon 6+ 'Clearwater Forest' for AI inference—China’s focus on CPU-driven exascale capacity provides a scalable model for autonomy. This results in a market where hardware selection is dictated by geopolitical alignment and the requirement for either mixed-precision AI speed or traditional double-precision scientific accuracy.
⚡️ The Convergence of Precision: Intel 8087 and the Co-processor Shift
100x fewer compute cycles! A massive leap in speed equivalent to replacing a manual ledger with a supercomputer ⚡️ Intel's 8087 coprocessor removes memory latency using a custom bar-shifter. Silicon vs. Software: is dedicated hardware still the only way to scale? Scientific researchers — does this precision change your workflow?
Intel's launch of the 8087 floating-point coprocessor on June 22, 2026, demonstrates a fundamental shift in computational architecture. By introducing an 80-bit operand width and integrating IEEE 754 support, the hardware achieves a roughly 100-fold reduction in compute cycles compared to software-emulated models, accelerating the processing of complex numerical data.
How the Bar-Shifter Accelerates Compute
The performance gain results from a custom bidirectional bar-shifter. This component utilizes pass transistors operating within a single metal layer, which enables the processor to execute floating-point operations internally. This architectural choice eliminates the requirement for external memory access during calculation, removing the latency typically associated with peripheral data retrieval.
Technical Impacts
- Precision: 80-bit width enables higher accuracy in scientific simulations; this bridges the gap toward 128-bit quadruple precision formats used in high-end scientific computing.
- Latency: Internal bar-shifting results in zero added latency for integrated calculations.
- Integration: ICE integration allows seamless execution on standard microprocessors without dedicated peripheral ports.
Evolution of the FPU Paradigm
The 8087 marks a transition where specialized hardware supplementation meets general-purpose processing. This development streamlines graphics rendering and scientific computing by shifting the burden of floating-point math from software emulation to dedicated silicon, mirroring the x86 instruction set's goal of establishing backward compatibility across generations.
- 2026: Launch of the 8087, establishing the high-precision coprocessor standard.
- Interim Period: Increasing adoption of FPU accelerators in engineering workstations.
- 1989: Full CPU-integrated FPU dominance, absorbing coprocessor functionality into the primary die.
- 2018: Release of Core i7-8086K, commemorating the 40-year legacy of x86 architecture.
Strategic Trade-offs
- Strength: Massive cycle reduction leads to immediate gains in computational throughput.
- Weakness: Dependency on a separate chip increases motherboard complexity before full integration.
- Competition: Challenges software-based libraries and faces long-term pressure from ARM-based platforms like RTX Spark.
This milestone indicates the final operational phase of the standalone co-processor paradigm. The efficiency gains demonstrated by the 8087 ensure that floating-point computation remains a permanent, embedded feature of processor architecture, paving the way for subsequent 64-bit and hybrid multi-platform solutions.
⚡ Scaling Quantum Trajectory Simulations
30% faster execution. This massive leap in quantum trajectory simulations is like shaving hours off a workday ⚡. Hardware-informed decomposition is breaking current bottlenecks. But can hybrid architectures scale before fault-tolerance arrives? R&D teams — how is this shifting your project timelines?
Recent developments in quantum trajectory modeling indicate a shift toward operational utility by integrating cost-resolved methodologies, hybrid classical-quantum architectures, and AI-driven calibration. On June 22, 2026, Aaron Sander and an international team introduced a framework that reduces execution time for open-system quantum model simulations by 30%.
How does resource optimization accelerate discovery?
The framework employs hardware-informed stochastic decomposition and modular resource adaptation to identify computational bottlenecks and allocate resources based on required fidelity. By decoupling high-precision requirements from less critical trajectory paths, the system reduces total floating-point operations per cycle.
This algorithmic progress is supported by emerging hybrid strategies. On June 14, 2026, EPFL researchers developed a quantum-enhanced classical algorithm capable of simulating 127-qubit system dynamics using classical patches to approximate quantum behavior. This coincides with a shift toward permutation matrix applications; analysis by Hriday Sabharwal and Itay Hen identifies resource efficiencies in permutation matrices over traditional algorithms for Rydberg and Floquet models.
Hardware integration further addresses latency. Q-CTRL and AMD recently unveiled automated calibration and FPGA-based AI algorithms to resolve bottlenecks where manual calibration previously required days. Moreover, NVIDIA's AI-enhanced software now accelerates classical tasks essential for quantum operations. These optimizations directly enhance material science; on June 2, 2026, Denso Corp and the Tokyo University of Science deployed quantum-enhanced Green-Kubo transport coefficients to predict thermal and electrical transport properties.
Operational Impact
- R&D Pipelines: 30% runtime reduction enables iterative prototyping of quantum algorithms.
- Resource Efficiency: SCSK Corp’s algorithm reduces MaxCut T-depth by 85.2%; EPFL’s 127-qubit simulation reduces classical overhead.
- Hardware Scalability: FPGA-based AI and AQT’s 20 mK QPU remove temporal bottlenecks for larger qubit arrays.
Performance Comparison
- Traditional Trajectories: High computational overhead $\rightarrow$ slow convergence in open-system models.
- Cost-Resolved Framework: Stochastic decomposition $\rightarrow$ 30% faster execution with preserved fidelity.
- AI-Driven Calibration: Manual processes (days) $\rightarrow$ AI-automated (minutes), increasing array viability.
Timeline of Adoption
- 2026–2027: Integration of cost-resolved frameworks and AI-calibration into primary quantum libraries.
- Q3 2026: Transition toward integrated classical-quantum architectures for resource allocation.
- 2027–2028: Commercial R&D adoption for materials testing and industrial fluid dynamics.
- 2029: Projected transition to mainstream fault-tolerant quantum systems.
The correlation between hardware-informed decomposition, AI-driven calibration, and hybrid classical-quantum simulation demonstrates that algorithmic optimization offsets current hardware limitations. These results project a transition where quantum simulations become viable for industrial application by 2028.

Comments ()