$1 Trillion AI Pivot: South Korea Targets Hardware Autonomy and 18.4GW Capacity
TL;DR
- $1 Trillion AI Pivot: South Korea Targets 18.4GW Capacity to Secure Hardware Autonomy. Can South Korea's energy grid support a 10x increase in AI data center capacity by 2035?
- $4.2M Fraud Surge: AI Integration Triggers Systemic Latency and Security Risks in Global Payment Gateways. Does the integration of AI-driven fraud detection compromise system performance and increase checkout latency for enterprise users?
- 90% Accuracy in Grid Compression: New AI Debugging Loops Slash Hallucinations Globally. Does the increase in API costs justify the higher precision gained through iterative AI debugging loops?
🇰🇷 South Korea Mobilizes $1 Trillion AI Infrastructure Pivot
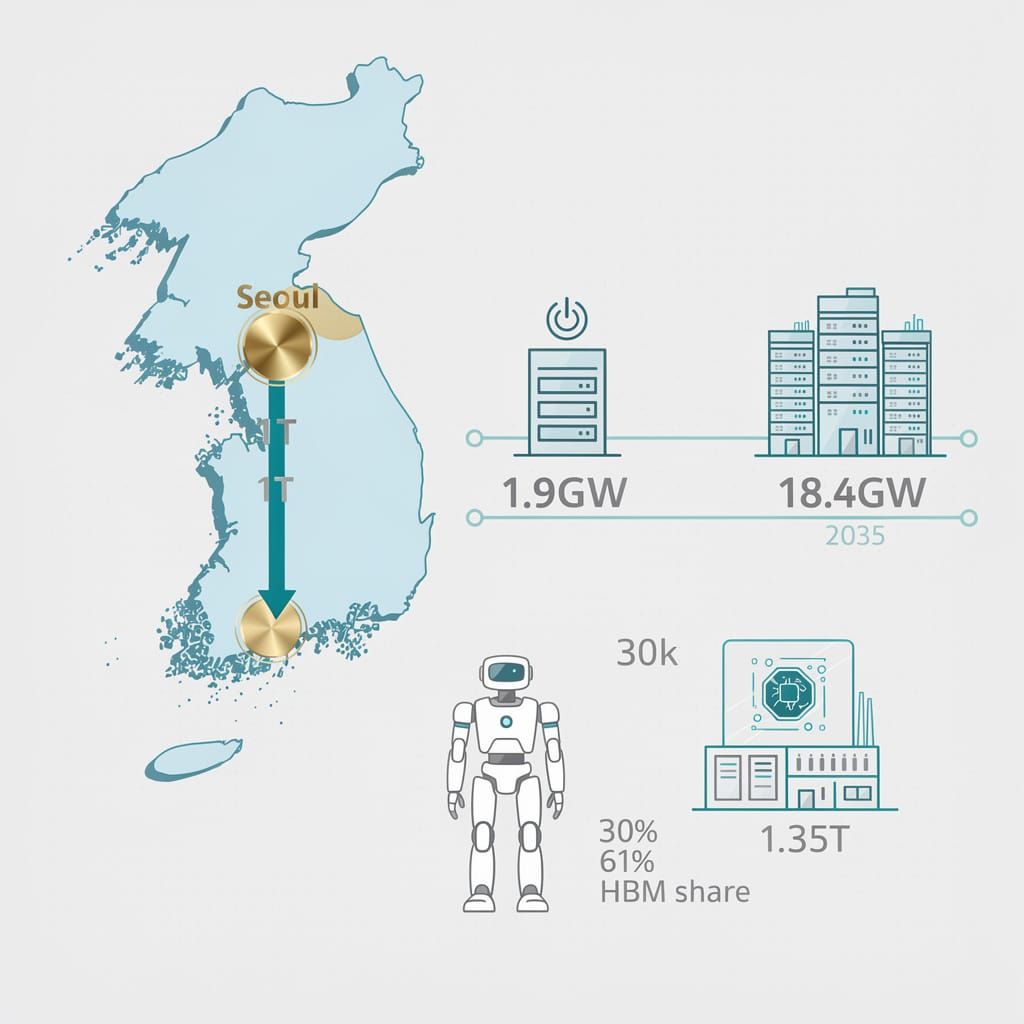
$1 Trillion: South Korea's massive gamble for AI autonomy is equivalent to nearly 10% of its GDP 🇰🇷. This pivot expands data capacity from 1.9GW to 18.4GW. Can energy grids survive this surge? Industrial workers — how do you feel about 30,000 Atlas robots entering the workforce?
South Korea has initiated a systemic structural shift in its semiconductor and artificial intelligence ecosystem to secure hardware autonomy. On June 29, 2026, President Lee Jae-myung announced a $1 trillion national investment plan targeting semiconductor clusters, AI data centers, and robotic hubs. This state directive catalyzes massive private capital, including a $585 billion joint venture between Samsung and SK Hynix to expand wafer plants in the southwest.
Why Decentralize the AI Hub?
Strategic mandates shift the economic center of gravity from Seoul toward Honam, Chungcheong, and Yeongnam provinces to mitigate geopolitical risks and resource concentration. The government provides fast-tracked permits to establish a vertical AI supply chain—integrating fabs, packaging, and substrate plants. This redistribution counters global volatility, such as the 9.3% drop in US markets seen in late May and early June 2026, by stabilizing domestic supply chains against external shocks.
How Does the Investment Scale?
Infrastructure: $1 trillion government commitment → expands data center capacity from 1.9 GW to 18.4 GW by 2035. Major contributors include SK (5 GW), GS (3.6 GW), and Naver (1 GW). Robotics: Hyundai's full acquisition of Boston Dynamics → targets the annual deployment of 30,000 Atlas humanoid robots by 2030 to automate manufacturing. Semiconductors: SK Hynix doubles DRAM wafer capacity by 2030 → enables a 61% HBM market share and a market capitalization of ~$1.35 trillion, surpassing Samsung's ~$1.34 trillion in June 2026.
What are the Technical and Systemic Risks?
Energy: 18.4 GW data center targets → increase grid strain, necessitating urgent renewable and nuclear upgrades. Market: High Capex → results in stock volatility; Samsung faces margin pressure as Chinese firms like CXMT ramp up memory production. Labor: Rapid humanoid deployment → triggers displacement in repetitive industrial roles and union resistance.
Deployment Roadmap
- Q4 2026: Completion of initial foundry facilities, enabling first-wave wafer production.
- Q1 2028: Technical breakthrough in data center phasing, initiating operational scaling.
- 2029–2030: Integration of Atlas robots into Hyundai's Metaplant and full-scale HBM supply stabilization.
- 2035: Achievement of 18.4 GW total AI compute capacity.
📉 The Friction of Automation: Balancing AI Integration and System Latency
$4.2M lost in 48 hours. This staggering fraud surge is like losing a mid-sized company's revenue in a weekend 📉. AI-driven synthetic rings are overwhelming static defenses. Can automation secure systems without killing latency? Enterprise users — is AI slowing down your checkout experience?
Operational efficiency in the AI-integrated enterprise now depends on the correlation between agentic automation and infrastructure stability. Recent systemic failures across payment gateways and the emergence of AI-fueled fraud rings demonstrate how rapid deployment exposes architectural vulnerabilities and amplifies operational overhead.
Does Automation Compromise Performance?
On June 30, 2026, reported p99 latency spikes in checkout systems indicated critical performance degradation. This follows a pattern of instability observed on April 23, 2026, where AI fraud detectors triggered excessive false positives, resulting in persistent payment rejections for gold-tier users. This causal chain demonstrates that the integration of AI event detectors and autonomous monitoring creates resource contention, which results in increased latency and checkout abandonment.
This friction is systemic. While AI aims to secure transactions, it has simultaneously lowered barriers for attackers. On June 22, 2026, coordinated fraud rings generated $4.2M in 48 hours using synthetic identities and transaction flows of 180 per minute. The reliance on static rules against these adaptive networks forces a reactive posture, where the pursuit of real-time detection often competes for the same compute resources required for primary service delivery.
Extending Cognitive Bandwidth
To counter organizational fragmentation, providers are shifting toward agentic orchestration. On June 23, 2026, Anthropic launched "Claude Tag" via Slack, powered by Claude Opus 4.8, automating task triage for over 470,000 employees. Concurrently, the development of MRAgent—a dynamic memory system—demonstrates a technical shift toward efficiency, halving inference time compared to A-MEM baselines and offering 5x faster response paths in LLM chains.
Integration Timeline
- June 23, 2026: Anthropic deploys Claude Tag into Slack for asynchronous task delegation.
- June 26, 2026: NUS researchers develop MRAgent to reduce AI agent inference latency.
- June 30, 2026: Detection of p99 latency spikes in checkout systems due to AI resource contention.
- July 01, 2026: US Commerce Dept withdraws export controls on Anthropic's Fable 5 and Mythos 5.
Systemic Impacts
- Operational: Automation of triage → reduced manual ticket sorting → faster developer response.
- Technical: Memory limitations (e.g., 9GB RAM on iPhone 18) → failure in runs exceeding 180K tokens.
- Security: Synthetic identity rings → $4.2M loss in 48 hours → erosion of digital trust.
- Financial: AI valuation skepticism → June 23 Nasdaq drop (2.2%) → 9.3% tech sector sell-off.
This duality indicates a growing tension. While agents reduce context-switching, the underlying hardware—marked by GPU procurement surges and memory caps—must evolve to prevent automation from degrading core service delivery.
📉 The Debugging Loop: Shifting from Consumption to Interaction
90% accuracy preserved in 6x10 pixel grids! This staggering precision 📉 mirrors human-brain concept decomposition. Higher logic consistency is reducing hallucinations, but at the cost of token spend. Commercial users — is the trade-off for precision worth the higher API cost?
On June 30, 2026, a behavioral pattern emerged across major AI interfaces, including OpenAI's GPT, Anthropic's Claude, and Google's Gemini. Users increasingly pause after initial responses to ask models why a specific answer worked. This indicates a transition from passive consumption to interactive debugging, forcing models to surface internal reasoning chains to mitigate hallucination risks reported in legal and medical sectors on June 19.
How Does Iterative Validation Work?
The process converts requests into a two-stage verification cycle. Requesting logic explanations triggers a self-correction mechanism that narrows the probability space for refinements, anchoring output to explained logic. This shift coincides with research into multimodal neurons published on June 14, which enables better interpretability by identifying how neural networks decompose concepts—including emotion and region neurons—drawing parallels to human brain function.
Technical breakthroughs support this precision. On June 11, researchers compressed long contexts into 6×10 pixel grids while preserving 90% referential accuracy. Additionally, the Prelim Attention Score (PAS) now allows real-time hallucination detection in vision-language models, creating a causal chain where explicit reasoning requests result in higher accuracy, albeit at the cost of increased token consumption.
User Experience
- Cognitive Load: Lowered frustration via predictable logic patterns.
- Workflow: Shift from single-prompting to template-based iterative loops.
- Efficiency: Higher precision per task despite increased total token usage.
Performance Trade-offs
- Accuracy: Higher logic consistency → reduced hallucination rates.
- Speed: Slower time-to-final-answer → increased latency per workflow.
- Cost: Higher API credit usage → elevated operational costs for power users.
The Trajectory of Human-AI Collaboration
Commercial adoption now favors integrated testing over single-shot queries. This is accelerated by a shift toward local-AI frameworks to mitigate cloud-dependency risks and regulatory tightening on transparency. Edge inference—enabled by AX Engine and MLX—moves this loop closer to the user. Benchmarks on the Gemma-4-26B-A4B model demonstrate this viability, achieving 40 tokens per second on an i9-13900K CPU without GPU acceleration via Mixture-of-Experts (MoE) architecture and bit-width quantization.
- Short-term (Q3 2026): Growth in guided prompting as firms navigate EU AI Act transparency audits and market volatility following a 9.3% tech-sector sell-off.
- Mid-term: Integration of "verification prompts" as native UI features to automate the debugging loop.
- Long-term: Shift in benchmarks from "first-response accuracy" to "convergence speed" (turns required to reach a verified answer).

Comments ()