$38.53B Loss: OpenAI Launches Jalapeño custom ASICs in US to Slash Inference Costs
TL;DR
- $38.53B Loss: OpenAI Debuts Jalapeño ASIC Platform to Slash Inference Costs. Can OpenAI's new Jalapeño custom silicon platform reverse its $38.53 billion net loss and reduce GPU dependency?
- Python 3.15: AST Vectorization Shifts Loop Execution to Parallel Lanes for 40% Faster Runtimes. Will Python's new built-in vectorization finally eliminate the need for external C-extensions in scientific computing?
📉 The Jalapeño Shift: OpenAI Enters the Silicon Race
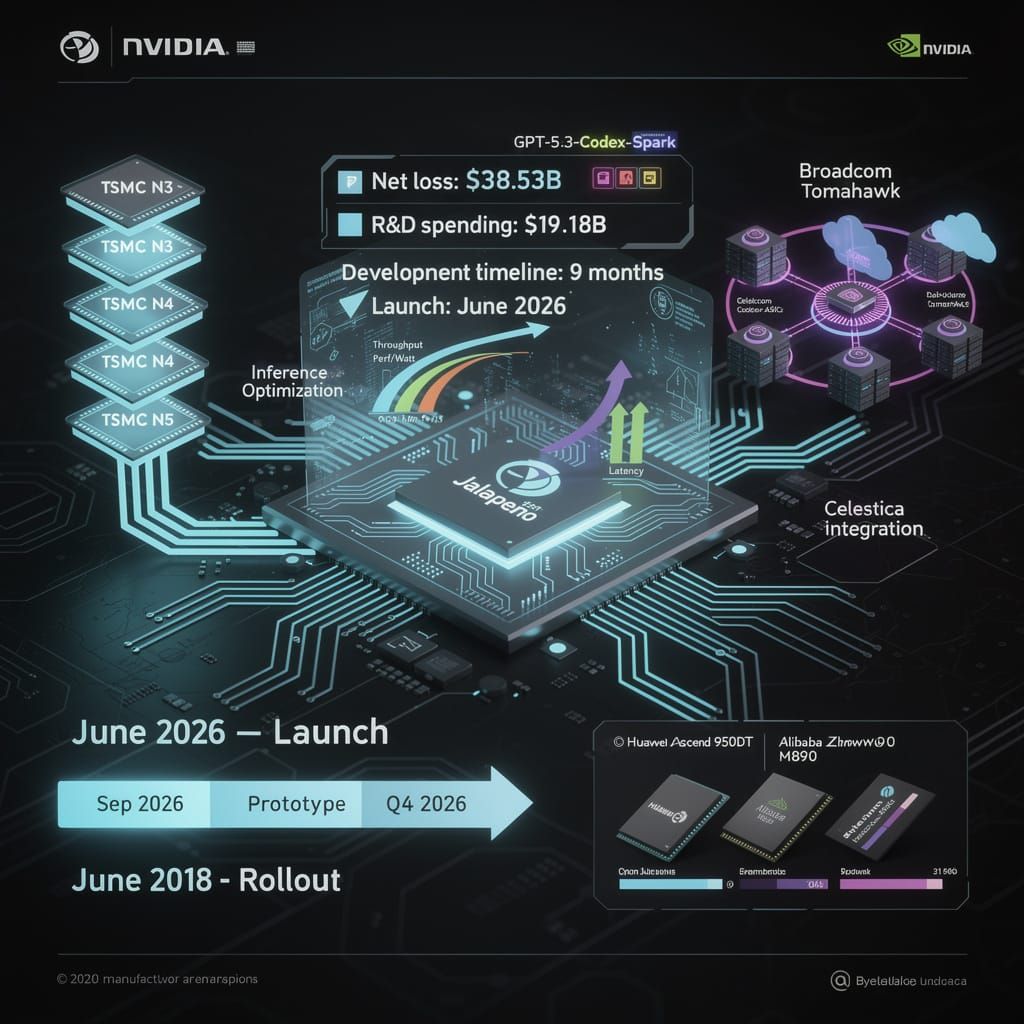
$38.53B net loss: a staggering deficit roughly 3x previous operating losses 📉. This financial pressure drove OpenAI to launch Jalapeño custom ASICs to cut costs. Can proprietary silicon save AI profitability? OpenAI — will custom chips end your GPU dependency?
On June 24, 2026, OpenAI and Broadcom unveiled the Jalapeño Intelligence Platform, marking OpenAI's strategic transition from a hardware consumer to a silicon designer. Developed in nine months, the platform utilizes custom Application-Specific Integrated Circuits (ASICs) produced by TSMC to optimize inference workloads by reducing data movement.
How Does the Architecture Function?
The system integrates Broadcom’s Tomahawk network technology with Celestica system integration to minimize latency. Unlike general-purpose GPUs, Jalapeño is engineered exclusively for inference, enabling the deployment of GPT-5.3-Codex-Spark directly into corporate networks. This custom hardware approach eliminates bottlenecks associated with general-purpose compute by tailoring the data path for higher performance-per-watt.
- June 2026: Launch of Jalapeño platform; testing of GPT-5.3-Codex-Spark begins.
- September 2026: Start of prototype production deployment.
- Q4 2026: Integration across major data centers to reduce operational overhead.
- June 2028: Full-scale global rollout projected.
What Drives the Move Toward Custom Silicon?
The shift results from a causal chain where GPU scarcity and unsustainable operational costs drive vertical integration. Audited financial records from June 17, 2026, reveal OpenAI reported a $38.53 billion net loss for 2025, with operating losses rising from $8.78 billion in 2024 to $20.92 billion in 2025. R&D spending climbed to $19.18 billion, while revenue reached $13.07 billion. Designing proprietary silicon allows OpenAI to mitigate these deficits and compete with the TPU and Trainium advantages held by hyperscalers.
Operational: Lower inference costs $\rightarrow$ reduced energy expenditure for ChatGPT services. Performance: Higher throughput $\rightarrow$ reduced latency and improved query response times. Financial: Custom ASIC scaling $\rightarrow$ path toward profitability via cost-efficient scaling.
The Competitive Landscape
OpenAI's pivot occurs as Nvidia reaches a $5 trillion market capitalization. While OpenAI maintains partnerships with Nvidia, the move serves as a hedge against vendor lock-in and geopolitical volatility. Tightening U.S. export policies and US-China trade tensions have constrained semiconductor supply chains, increasing the risk for firms reliant on a single provider. This trajectory indicates a dissolution of the boundary between software providers and hardware manufacturers:
- Huawei: Launched Ascend 950DT.
- Alibaba: Deployed Zhenwu M890 AI agent processor.
- ByteDance: Negotiating custom ASICs with Qualcomm.
This shift toward proprietary hardware maximizes compute efficiency at the exascale level while insulating firms from the valuation volatility and capex pauses currently affecting the broader AI-chip sector.
🚀 Vectorizing Python: A Shift in Loop Execution
40% runtime reduction is an astronomical shift—equivalent to reclaiming hours of compute time weekly 🚀. Python's new AST-based vectorization transforms sequential loops into parallel lanes. Speed vs. Complexity? Data scientists — will this replace your C-extensions?
On June 25, 2026, the introduction of a lightweight Python-based compiler shifted the execution profile of the language by converting standard sequential loops into parallel vectorized formats. This system analyzes Abstract Syntax Tree (AST) nodes to determine value uniformity and variability, rewriting iterative loops into vector_for constructs. This mechanism enables the runtime to execute code via lane-based execution across concurrent processing units without altering the original program logic.
How does the parser optimize throughput?
Traditional Python loops execute sequentially, limiting the utility of multi-lane hardware. The new compiler acts as a translation layer that maps loop patterns to parallel vectors using masks and gathers, enabling simultaneous operations across multiple data lanes. This architectural shift correlates the number of hardware lanes directly to latency reduction, which is particularly evident in compute-heavy tasks such as audio scaling.
This optimization aligns with the Python 3.15 beta's broader performance initiative, which introduced a new JIT compiler and a stable ABI to increase CPU efficiency and concurrency support. By removing the deprecated incremental garbage collector and introducing frame pointer support, the environment enables more precise observability and reproducible profiling during vectorized execution.
System Mechanics:
- Parsing: Compiler analyzes AST nodes to identify serial loop structures.
- Transformation: Rewrites sequential loops into
vector_forparallelized forms. - Execution: Runtime distributes operations across hardware lanes via data parallelism.
Performance Impacts:
- Latency: Decreases proportionally as lane counts increase.
- Throughput: Higher data volume processed per clock cycle via optimized SIMD/SIMT utilization.
- CPU Efficiency: New JIT compiler and stable ABI reduce overhead for concurrency.
- Observability: Frame pointer support enables tighter performance tuning.
Future Performance Trajectory
Integrating vectorization into Python's flow indicates a move toward tighter hardware-software integration for scientific computing. This trajectory mirrors efficiency gains seen in GPU-accelerated libraries and compiled ML stacks that utilize ILP/TILE patterns to reduce latency.
- Q4 2026: Integration into developer toolchains; projected 20%–40% runtime reduction for data-heavy loops.
- 2027: Expansion to support diverse accelerator architectures (GPUs/NPUs), doubling throughput for parallelizable tasks.
- 2028: Standardization of lane-based execution in high-performance distributions, reducing reliance on external C-extensions.
Hardware Synergy:
- Modern CPUs: Optimized code paths result in higher instruction throughput.
- GPUs/NPUs: Vector formats enable direct mapping to Tensor Cores and SIMD-capable hardware.
- Enterprise: Improved typing safety in 3.15 reduces runtime errors during large-scale parallel deployments.



Comments ()