MIT FFM Slashes Transformer Compile Time 12×: Linear Scaling Breakthrough Reaches National Labs
TL;DR
- MIT researchers develop FFM algorithm that linearly scales tensor fusion mapping, reducing search space exponentially for HPC workloads
- Bambu Lab Unveils H2C Desktop 3D Printer with 4-Tool Head System, 320x320mm Build Volume, and $2,399 Price Point
⚡ MIT's FFM Mapper Achieves 12× Compile Speedup: Linear Scaling Breaks Exponential Tensor-Fusion Bottleneck for Exascale AI
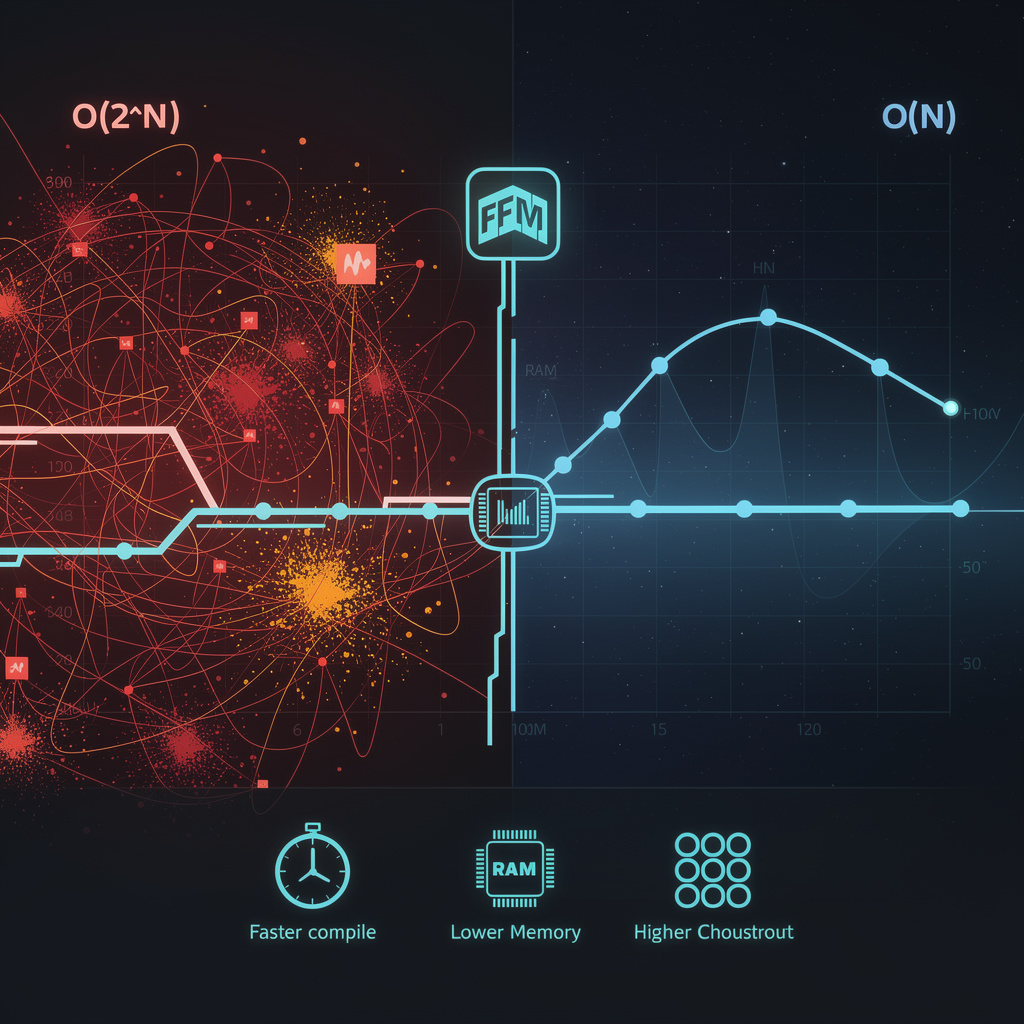
12× faster compilation on 24-layer transformers: MIT's Fast and Fusiest Mapper (FFM) just cracked the exponential tensor-fusion problem with linear O(N) scaling. 🧠 Hours→minutes for 50+ layer models, cutting RAM pressure from O(2^N) to O(N). Oak Ridge & Argonne adopting Q4 2026—but will your HPC center wait for exascale defaults or integrate early?
MIT researchers have delivered a concrete fix to one of high-performance computing's most stubborn bottlenecks: the combinatorial explosion of tensor-fusion mapping. Their Fast and Fusiest Mapper (FFM) algorithm, published February 22, 2026, prunes suboptimal mappings to achieve linear-time scaling—transforming compilation from an exponential drag into a manageable step for AI and scientific workloads.
How does FFM eliminate the search-space explosion?
Traditional fusion mappers explore the full mapspace, incurring O(2^N) complexity for N computation steps. FFM systematically eliminates suboptimal subsets during construction, building only optimal fusing mappings. Empirical tests on Intel Xeon CPUs paired with NVIDIA A100 GPUs demonstrate O(N) runtime—roughly 12× faster compilation on a 24-layer transformer benchmark versus the best heuristic alternative. Memory pressure collapses correspondingly: peak mapspace storage drops from exponential to linear, freeing RAM for actual computation rather than search overhead.
What gains materialize across the stack?
- Compile time: Hours-long compilation for 50+ layer models compresses to minutes, enabling rapid architectural iteration.
- Memory footprint: O(2^N) to O(N) reduction in mapspace storage eases cluster RAM constraints.
- Training throughput: Early integration on an 8-node DGX-A100 cluster shows 1.8× more epochs per day for a 175 billion-parameter model—equivalent to shaving weeks off large training runs.
- Exascale compatibility: Linear mapping cost aligns with job schedulers' limited compile slots, embedding cleanly into systems like Frontier-II (2028).
Where do risks and responses stand?
| Risk | Mitigation |
|---|---|
| Integration complexity with TVM/XLA | C++/Python API conforming to TAPP low-level interface; reference adapters for TVM 0.12 and XLA 2026 |
| Hardware-specific portability limits | Parameterized pruning thresholds with device-capability descriptors for varying tensor-core shapes |
| Optimality verification on irregular graphs | Exhaustive fallback mode for regression testing; 30-kernel benchmark suite |
What does the deployment timeline indicate?
- Q3 2026: MIT-licensed open-source release; PyTorch-XLA demo on Google TPU v5e.
- Q4 2026: Oak Ridge and Argonne adoption for GPU-rich clusters; 70% compilation-time reduction on climate-simulation kernels.
- 2027: TAPP-WG reference implementation inclusion; standardized "fusion-map" descriptors in the Tensor Algebra Processing Primitives specification.
- 2028–2030: Default pass in exascale compilation flows; extension to neuromorphic and photonic accelerators; projected 5% reduction in training energy consumption through shorter compile times.
FFM's deterministic fusion mapping addresses a structural limitation that has constrained accelerator utilization across HPC and AI. By replacing exponential search with linear construction, it enables compilers to keep pace with hardware advances rather than lagging behind them—a shift that positions tensor-fusion optimization as an enabler rather than a bottleneck for exascale-era workloads.
🧪 $2,399 Desktop Foundry: Bambu H2C Redefines Professional 3D Printing
4 extruders. 24 filaments. $2,399. 🧪 The Bambu H2C isn't a printer—it's a desktop foundry. 8-second cooling, laser-ready, but locked in proprietary software. Will your lab pay 6× the hobbyist price for multi-material freedom?
Bambu Lab has positioned its H2C at a precise inflection point in desktop manufacturing: the $2,399 multi-tool printer signals that professional-grade multi-material fabrication has migrated from industrial floors to engineering workstations. Released February 22 from the company's Fort Knox distribution hub, the H2C packs four independent extruder heads, 320×320×325 mm build volume, and a sensor array rivaling some industrial setups—three 1080p cameras and seven microphones feeding real-time process monitoring.
How does the four-head architecture change production workflows?
The H2C's quad-extruder layout departs from conventional single-nozzle or dual-extruder desktop systems. Each head carries dedicated thermal management with 8-second cooling cycles, enabling simultaneous deposition of incompatible polymers without cross-contamination. The configuration supports 24 distinct filament channels through AMS 2 Pro integration, including engineering-grade materials up to 85°C—nylon, polycarbonate, and fiber-reinforced compounds previously requiring industrial machines. CoreXY kinematics with vibration-compensation algorithms maintain dimensional accuracy across the 32.8-liter build envelope, while automatic bed leveling and closed-loop feedback from the camera array reduce first-layer failure rates.
What trade-offs define the H2C's market position?
Capability: Multi-material assemblies in single prints—compliant mechanisms, embedded electronics, graded stiffness structures—eliminate post-assembly steps.
Cost: At six times the price of Bambu's entry-level P1S ($399) and twelve times Anycubic's Kobra 3 V2 (~$199), the H2C filters for organizations with allocated prototyping budgets.
Complexity: Synchronized four-head operation increases calibration overhead; maintenance demands scale with hardware count.
Ecosystem: Deep Bambu Studio integration streamlines workflow but risks pipeline isolation without open APIs for external simulation tools.
Where do adoption barriers persist?
The optional $800 laser/cutter module extends functionality into subtractive processing, yet regulatory clearance for laser add-ons may delay European and Asian rollouts. Material cross-contamination between heads—critical for conductive or fiber-filled filaments—remains unproven at scale. Academic and medical device prototyping groups, identified as early adopters, will likely stress-test nozzle synchronization protocols within months.
What trajectory does the H2C establish?
- 2026–2027: ~15,000 units projected for North American professional and university labs; early feedback drives firmware refinements on inter-head coordination.
- Q4 2027: Competitor response materializes—dual and triple-extruder variants from Anycubic, Prusa, and Formlabs—but sensor density and laser integration maintain H2C differentiation.
- 2028–2029: "Desktop foundry" category formalizes; hybrid additive-subtractive systems become standard for engineering workstations, pressuring pure-play 3D printer margins.
The H2C does not democratize multi-material printing—it professionalizes it. By compressing industrial capability into a $2,400 footprint with consumer-grade usability, Bambu Lab has redrawn the boundary between hobbyist experimentation and production-ready prototyping. Whether this catalyzes broader HPC integration or deepens proprietary silos depends on API accessibility and third-party simulation toolchain adoption in the coming release cycles.
In Other News
- IonQ achieves 99.99% two-qubit gate fidelity, setting new benchmark for quantum computing accuracy and commercial viability
- Windows 10 end-of-support triggers mandatory upgrade to Windows 11 or ESU plan with TPM 2.0 and UEFI requirements



Comments ()