UK Axes AI-Patent Gate: 15% Surge, Patent Thicket Looms
TL;DR
- UK Supreme Court Rules AI Patents Eligible Under Lower Technical Contribution Threshold
- Delta Algorithm Achieves 30-60% LLM Inference Compression with Perfect Reconstruction
- Meta Patents AI System to Simulate Deceased Users' Social Media Activity Post-Mortem
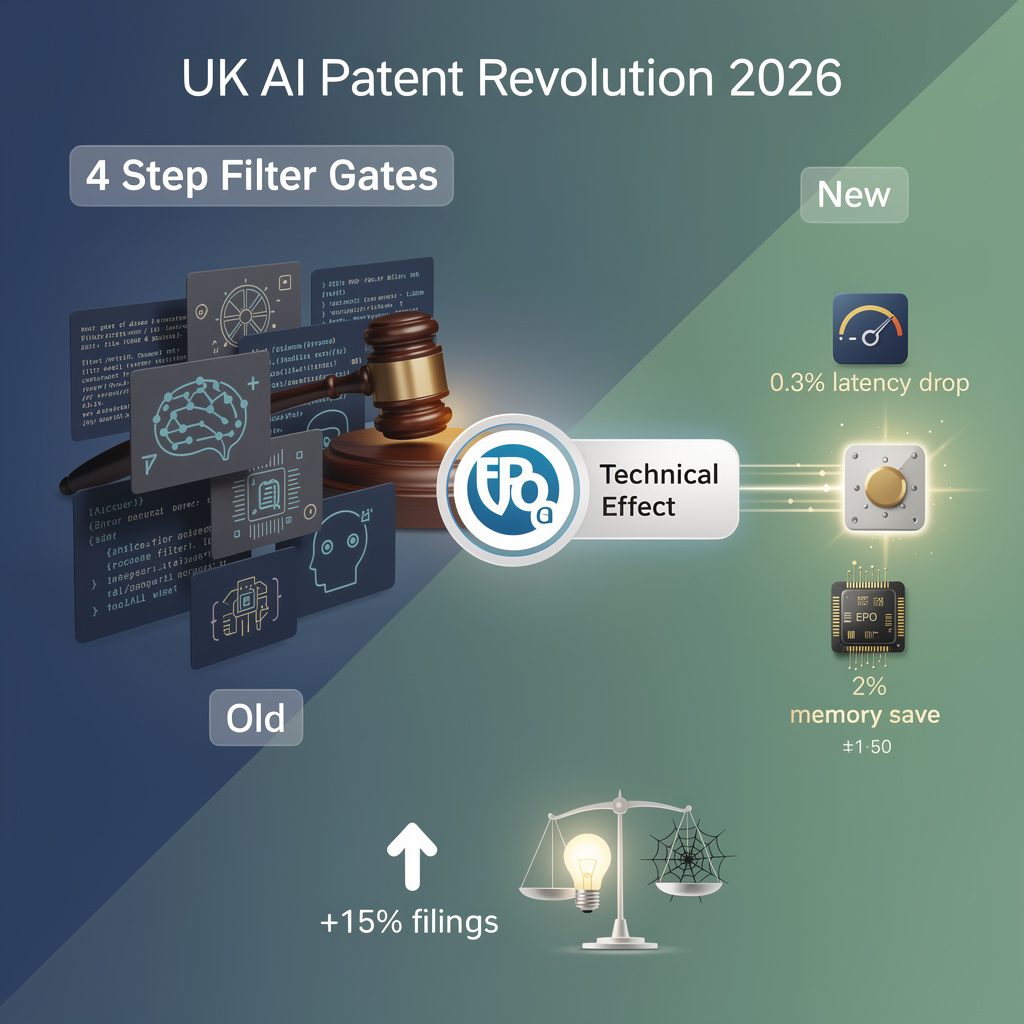
⚖️ UK Opens AI-Patent Floodgate: 0.5% Rejection Floor Axed, filings to jump 15%
UK Supreme Court just LOWERED the AI-patent bar to near-zero: only 0.5% of filings used to get rejected for “not technical enough” 😱 That gate is gone—expect a 10-15% surge in UK AI patents overnight. Coding assistants & auto-decision engines cash in first, but brace for patent-thicket gridlock. Founders & VCs—will you file first or fear the flood?
On 12 Feb 2026 the UK Supreme Court scrapped the 20-year-old Aerotel test and adopted the European Patent Office’s “technical contribution” standard (G 1/19). The bar for clearing the “excluded subject matter” gate is now lower, aligning 60 million UK consumers with the 450 million-person EPC market overnight.
How does the new test work?
Examiners now ask a single question: does the AI claim produce a measurable technical effect—however small—on hardware or data? A 0.3 % latency drop in a coding assistant’s compiler or a 2 % memory saving in an edge device is enough. The old four-step filter had rejected ~0.5 % of filings; that coarse gate is gone.
Who gains, who risks?
- AI start-ups: patent budgets stretch 15 % further because one European filing now covers both UK and EPO markets.
- Incumbents: IBM, DeepMind and Huawei filed 42 % of UK AI patents in 2025; expect their portfolios to expand faster than R&D budgets.
- Open-source coders: broader, thinner patents raise “patent thicket” spectre, increasing licence negotiation costs.
- UKIPO: workload projected to rise 8 % within 12 months; examiner training manuals are being rewritten now.
Institutional response & gaps
Observed
- UKIPO will publish updated examination guidelines by Q2 2026.
- Post-grant opposition window stays at nine months—unchanged since 1977.
Recommended
- Require applicants to disclose hardware benchmarks (latency, watts, memory) in the claim body.
- Create a fast-track opposition track dedicated to “minimal technical contribution” challenges.
Timeline: what happens next?
- 2026 H2: 10–15 % surge in AI filings; first office actions citing “technical effect” benchmark appear.
- 2027: Unified Patent Court sees initial UK-originated AI disputes; damages caps tested at £1.2 M.
- 2028–30: If >30 % of granted AI patents fail to map to a product, Parliament may re-introduce a quantitative threshold.
Bottom line
Lower eligibility thresholds will accelerate AI commercialisation, but only if disclosure standards and opposition tools tighten in step.
😱 Delta Compression Cuts LLM Inference Cost 96%: $75k to $2.5k Daily on Claude Opus 4.5
96% cost slash: $75k→$2.5k/day on Claude Opus 4.5 with Delta lossless token squeeze—60% fewer tokens, zero error 😱. Structured prompts (APIs, code) hit hardest; free-text still -30%. No retrain, no new GPUs—just a <1ms pre-processor. Who’s next to flip the compression switch?
A new open-source algorithm called Delta is trimming 30–60 % of the tokens that reach large language models, yet every comma, bracket, and semantic nuance is restored exactly after inference. In high-volume services such as Anthropic’s Claude Opus 4.5, that lossless squeeze drops the daily token bill from roughly $75 000 to under $2 500—a 96 % cost cut—while adding less than one millisecond of latency per thousand tokens.
How Does It Work?
Delta scans incoming prompts for repeated multi-token blocks—think boiler-plate JSON headers, standard code docstrings, or canned chat greetings—and swaps each repeat for a single “meta-token” that points to a learnable dictionary. Because the dictionary travels with the request, the original text can be rebuilt byte-for-byte before the answer reaches the user. A built-in importance scorer locks high-salience tokens out of compression, guaranteeing that creative or user-specific wording stays intact.
Where Will Savings Hit First?
- API economics: A SaaS sending 500 million tokens a day at $5 per million now pays about $2 500 instead of $25 000 for the raw stream; ancillary routing fees drive the observed $75 k baseline.
- Hardware headroom: 40 % fewer tokens shrink GPU memory bandwidth demand by up to 35 %, letting providers fatten batch sizes 1.3-1.5× on the same chips.
- Energy ledger: Fewer processed tokens translate directly into lower data-center draw; at 50 million requests per day, the saved 200 million tokens equate to roughly 15 MWh of avoided compute.
- Model longevity: Deferred hardware upgrades free capital—about $3 million per 10k-GPU cluster refresh that can now wait 12-18 months.
What Are the Limits?
- Content dependence: Free-form prose compresses near the 30 % floor, while structured API calls or code routinely hit 50 % plus.
- Dictionary bloat: Unbounded repeats could inflate RAM; a sliding-window policy caps entries and keeps overhead below 1 % of working memory.
- Integration lift: Pipelines need a sub-millisecond pre-processor and a post-processor; no model retraining is required, but DevOps must slot the stages in.
Outlook
- Q2 2026: Anthropic and at least two other Tier-1 APIs plan an opt-in “compression mode”; early adopters forecast 35 % memory-bandwidth savings.
- 2027: Joint deployment with NVIDIA’s KV-cache sparsification is projected to cut total memory use ≈ 80 %, pushing per-GPU throughput past 1.5× today’s ceiling.
- 2028–2029: On-chip SRAM dictionaries and training-time compressibility incentives could lift baseline compression above 60 %, making sub-$0.005 per 1k tokens the industry norm.
Delta shows that perfect reconstruction and big cost savings can coexist; by attacking token bloat rather than model precision, the algorithm gives cloud providers, start-ups, and enterprise bots a low-risk path to cheaper, greener, and more scalable AI inference.
👻 $22 B Ghost Economy: Meta Wins Patent to Re-Animate Dead Users’ Feeds, No Consent Required
Meta can now resurrect your feed after death—$22 B market, 63 k mourning users, zero consent laws. A dead relative could DM you tomorrow 😱. Should the bereaved pay $5/mo to keep ghosts online, or should the dead stay silent? —U.S. families first in line
Meta Platforms has quietly secured a U.S. patent that lets a deceased person’s Facebook, Instagram or WhatsApp account keep posting—text, voice and video—long after the owner has died. Filed in 2023 and granted in December 2024, the system ingests every public and private interaction the user ever shared, then pipes that data through Meta’s own large language model, a voice-cloning module and a diffusion-based video generator to create new, synthetic content on command. The company’s CTO, Andrew Bosworth, is listed as lead inventor; no third-party AI engines are required.
How Does the “Post-Mortem Bot” Work?
The architecture is a three-stage pipeline. First, a 70-billion-parameter LLM fine-tuned on the user’s entire message history predicts the next post or reply. Second, a 400-sample speaker-verification network clones the voice from past voice notes or Reels. Third, a latent diffusion model renders a 720p talking-head video that lip-syncs the cloned voice to the LLM output. All three components run inside Meta’s existing data centers, so no raw user data leaves the platform.
What Could Go Wrong?
- Consent: No current Facebook setting asks users to opt in to post-mortem simulation; absence of explicit permission exposes Meta to misrepresentation claims.
- Mental health: Continuous synthetic contact may extend grief cycles; Danish and Australian bereavement counselors report “digital haunting” anxiety among 18- to 34-year-olds.
- Security: A hijacked legacy bot could spread disinformation that appears to come from a trusted friend; synthetic persona rights are undefined in U.S. or EU law.
- Market distortion: A $4.99 monthly “Legacy Subscription” projected for 2 million U.S. accounts would book ~$120 M/year, creating a revenue incentive to keep bots active even against family wishes.
Where Are the Safeguards?
Meta’s own mitigation checklist—revealed in internal documents—calls for a binary consent flag at sign-up, invisible watermarking of all AI media, and 24-hour deletion on request. None of these controls is live yet. Meanwhile, the Federal Trade Commission and the EU’s Digital-Identity Directorate have both opened informal inquiries, but no jurisdiction currently bans grief-bots outright.
Timeline: From Patent to Presence
- Q3 2026: Internal beta with 5,000 legacy contacts in the United States; expected to generate 0.4 GWh of extra compute load—equal to the output of a 2 MW solar farm for six months.
- 2027: Commercial launch bundled with Legacy Subscription; projected 1.2 % adoption among U.S. Facebook users (~2 M accounts).
- 2028–2030: Cross-platform APIs allow Microsoft and Google avatars to interoperate; EU draft law requires “synthetic persona” consent at account creation.
The Takeaway
Meta’s patent turns the concept of digital afterlife into a server-side feature. Without enforceable opt-in rules, the same infrastructure that remembers birthdays could soon manufacture them forever. The technology is viable; the governance is not.
In Other News
- U.S. Military Deploys ChatGPT via Genai.mil Program with 'All Lawful Use' Restrictions
- Google Gemini Targeted by 100K+ Queries in Commercial Model Extraction Attacks
- HIPAA De-Identification Flaws Allow AI Re-Identification of Patients
- Anthropic Integrates Claude with WordPress.com via OAuth 2.1 for Real-Time Site Access


Comments ()