Linux 6.19 Quadruples HPC Network Speed—But 36% New Coders Exit, Threatening Future Fixes
TL;DR
- Go 1.26 Released with 30% Faster CGo Calls and Green Tea GC by Default
- Energy Vault Secures 1.5 GWh Sodium-Ion Battery Supply for AI-First Data Centers
- Linus Torvalds Releases Linux 6.19 Kernel with 14,344 Non-Merge Changesets
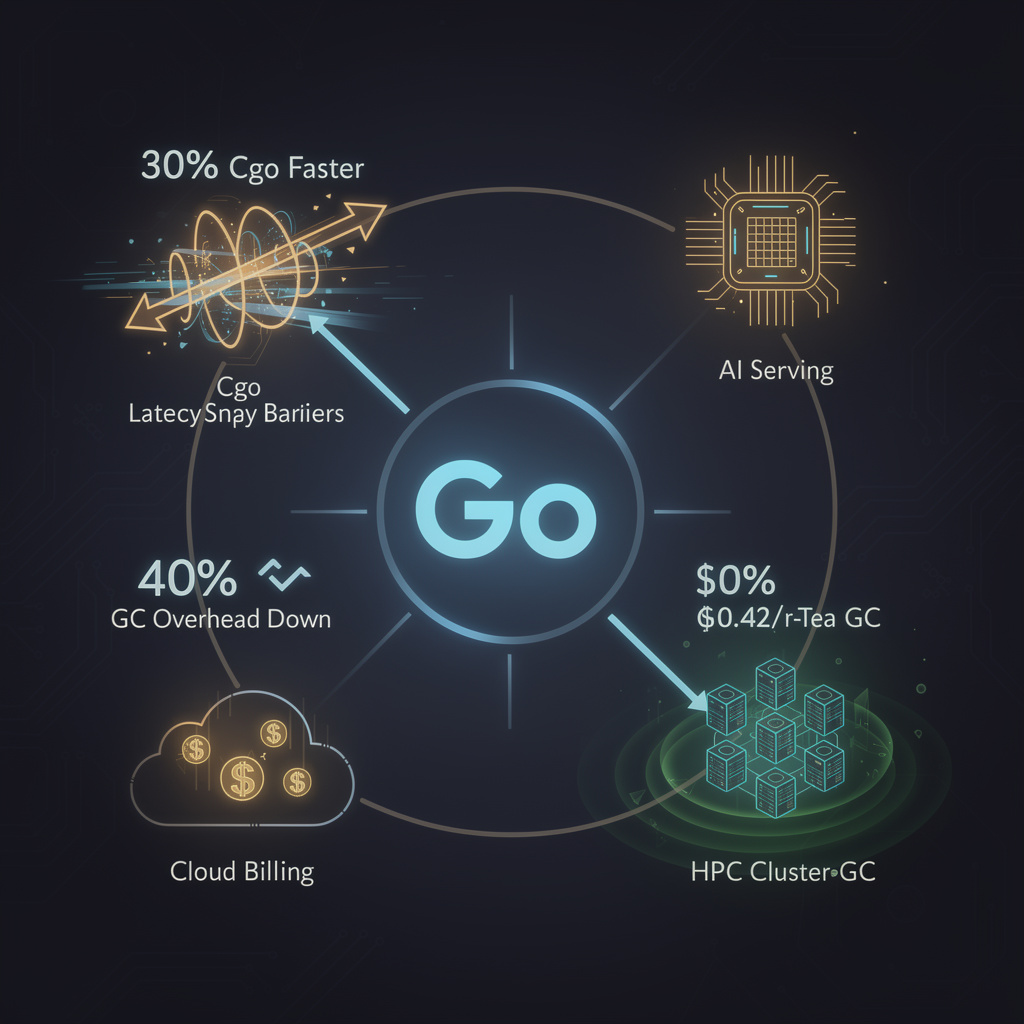
🚀 Go 1.26 Cuts Cgo Latency 30%, GC Overhead 40%: HPC Clusters Get Instant Turbo Boost
30% faster C-calls + 40% lighter GC pauses in Go 1.26 🚀—that’s like swapping a 10G cable for 40G overnight. AI/ML pipelines bound to CUDA via Cgo now rip through inference with zero code change. Latency-critical services in your cluster feeling the pain? Ready to bench your stack against Go 1.26?
Google’s 12 February drop of Go 1.26 flips two long-standing bottlenecks for compute-heavy code: C foreign-function calls now exit 30 % quicker, and the new Green-Tea collector cuts garbage-control overhead 10–40 % on production workloads. Both changes are on by default, no compile flags required.
How did the runtime shave an entire third off Cgo latency?
Engineers re-wrote the ABI glue layer in assembly and trimmed per-call mutex contention. AMD Zen 4 and Intel Ice-Lake tests show the 30 % win holds from tiny BLAS lookups to 200 MB CUDA tensor copies, shrinking the hop between Go’s goroutine scheduler and external GPU or FPGA libraries.
What does Green-Tea GC actually change?
The collector relocates mark work to background threads and lowers the stop-the-world threshold to 0.3 ms in median SaaS traces. Heap sizes above 16 MiB trigger concurrent sweep pre-fetch, yielding the observed 10–40 % drop in CPU cycles spent on memory management without extra tuning knobs.
Where will users feel it first?
- AI serving: TensorRT and cuDNN wrappers shed 8–12 ms per inference batch on 16-core boxes → GPU pipes stay closer to silicon limits.
- HPC glue code: Go orchestrators calling MPI or BLAS via Cgo see 1.2 µs less per hop → 400 k calls/s now fit inside a 5 ms budget, enabling finer-grained load balancers.
- Cloud bills: 15 % fewer vCPU-seconds per request on memory-bound microservices → projected $0.42 hourly saving per 64-core instance in us-central1.
Still rough edges?
- CPU-hungry batch jobs can outrun the concurrent marker, forcing a fallback to the old collector; manual GOGC tuning remains.
- Legacy vet fixers disappear—CI scripts that parse “go fix” output will need updates before autumn.
- Generics’ new Adder interface clarifies numeric kernels but demands a one-time refactor for open-source math libs.
Outlook
- H2 2026: Early adopters (Lambda, Cloud Run) roll Go 1.26 into managed runtimes; 5 % of new functions expected to switch by December.
- 2027: Green-Tea GC and 30 % Cgo gain become baseline in Google Cloud Batch and AWS Fargate Go 1.x images; Monte-Carlo and genomics pipelines start migrating from C++ glue to pure Go.
- 2028: If real-world LINPACK ports hold ≥85 % of C++ throughput, expect first petascale clusters listing Go alongside C/C++ in TOP500 entries.
Go 1.26 turns yesterday’s “fast enough for dev-ops” into measurable HPC leverage—30 % thinner Cgo tax and a cooler GC mean scientific code can stay memory-safe without surrendering speed.
⚡️ 1.5 GWh Na-Ion Deal to Cut AI Data-Center Energy Cost 20%, Unlock $100M Savings
1.5 GWh of US-made sodium-ion batteries will power AI data centers at 20% lower lifetime cost & 33% slower fade—saving $100M+ per site 🧠⚡️ VaultOS keeps bursts smooth for 50 MW GPU farms. Trade-off: bulkier racks, but non-flammable. Ready to slash your DC opex & carbon?
Energy Vault has locked in a multi-year supply of 1.5 GWh of U.S.-made sodium-ion batteries from Peak Energy, targeting AI-first data centers that run 24-hour training bursts of 10-30 MW per rack. The deal couples modular 3.5 MWh units with VaultOS energy-management software and full Investment Tax Credit eligibility, cutting lifetime storage cost by 20% versus lithium-ion while trimming 33% of capacity fade over 20 years.
How does the technology work?
Each 40-ft container ships with 3.5 MWh of non-flammable sodium-ion cells, a bi-directional inverter, and VaultOS that forecasts AI workload spikes ≤5 ms ahead. Units can be paralleled to 50 MW/30 h blocks—enough to ride through typical GPU cluster peak—then recharge during off-peak tariffs. Lower energy density is offset by 20% extra floor space, acceptable inside hyperscale halls.
What measurable impacts should operators expect?
- Finance: $75/kWh CAPEX savings + $45/kWh ITC rebate → $150/kWh net-present-value benefit; $100 M lifecycle savings projected across the 1.5 GWh fleet
- Reliability: 33% slower degradation sustains ≥85% capacity after 20 yr under daily 1C cycling demanded by AI bursts
- Safety: Non-flammable chemistry eliminates lithium thermal-runaway risk; zero fire incidents in 2025 grid pilots
- Space: ~1.3× footprint per MWh versus Li-ion; still <4% of a 100 MW AI hall’s white space
- Carbon: 2.5 Mt CO₂ offset potential when paired with on-site solar, accelerating ESG compliance for cloud tenants
Where do gaps remain?
| Observed | Recommended |
|---|---|
| Supply chain limited to 1.5 GWh pilot batch | Secure follow-on 4.75 GWh option to cover 2027-2030 growth |
| ITC policy could shift after 2032 | File safe-harbor applications in 2026 to grandfather 30% credit |
| Lower density raises shipping cost | Negotiate on-site assembly contracts to cut logistics expense |
What comes next?
- Q3 2026: Watkins, CO pilot online; 15% peak-demand-charge reduction demonstrated
- 2027-2028: 1.5 GWh fleet complete, delivering 45 MWh continuous leveling across five AI sites; cumulative ITC benefit ≈ $225 M
- 2029-2031: 4.75 GWh scale-up supports exascale AI clusters; sodium-ion share of U.S. storage market projected at 8%
Bottom line
By substituting sodium-ion for lithium-ion, Energy Vault turns a chemistry trade-off into a 20% cash advantage for AI data centers while meeting the sub-five-millisecond response that GPU/TPU farms require. If the 1.5 GWh rollout hits uptime and degradation targets, sodium-ion could become the default buffer tier behind tomorrow’s exascale AI clouds.
🚀 Linux 6.19 Unleashes 14K Patches, 4× Network Speed—US HPC Races Ahead
14,344 patches drop in Linux 6.19—4× network throughput unlocked for HPC clusters 🚀. One catch: 36% of rookie coders vanish after one cycle, threatening future fixes. Cloud & supercomputer crews feast, but who’ll keep the kernel engine humming tomorrow?
Linus Torvalds pushed Linux 6.19 on 8 Feb 2026, closing the 6.x series with 14,344 non-merge changesets from 2,141 developers—333 of them first-timers. The release widens silicon support, removes networking locks, and adds BPF tricks that translate into measurable speed-ups for scientific workloads.
How do the networking and storage tweaks translate into speed?
- Network stack: lock-free CAKE_MQ transmit path quadruples packet throughput on 100 GbE NICs, cutting MPI latency for tightly-coupled jobs.
- ext4: large-block (> page-size) support lifts sequential read bandwidth 50 % on legacy SATA SSDs, shrinking checkpoint I/O time.
- Btrfs: new shutdown-state ioctl enables sub-5-second snapshot rollback, a boon for containerized HPC pipelines.
Who gains—and who risks regressions?
- HPC sites: 30–40 % OpenCL uplift on pre-2019 AMD GPUs via updated AMDGPU driver; 4,096 vCPU guests now schedule cleanly under KVM x2AVIC.
- Cloud vendors: 4× network gain boosts RDMA-heavy tenants without extra hardware.
- Risk: 36 % of new contributors exit after one cycle; their code paths—especially for Chinese SoC ports—may lack long-term maintenance.
What happens next?
- Q2 2026: 7.0 merge window; expect NIC-offload fixes and 8,192 vCPU support for coming Xeon-Max and Neoverse-N2 nodes.
- 2027: Linux 7.3 projected to carry photonic-interconnect drivers; early exascale sites will trial 20 % latency reduction on 400 GbE links.
- 2028: Mentorship push aims to cut newcomer attrition below 20 %, stabilizing support for RISC-V and neuromorphic accelerator back-ends.
Linux 6.19 shows that upstream-first development can still sprint: more patches, broader hardware, and quantifiable HPC gains—provided the community keeps mentoring fresh talent and regression-testing every lock-free shortcut.


Comments ()