90% Neural Net Accuracy Achieved Without Moving Data — New RRAM Chip Redefines HPC Energy Limits

TL;DR
- New HPC Framework Floecat Unifies Fragmented Lakehouse Metadata Across Clouds
- RRAM Breakthrough Enables In-Memory Computing, Achieving 90% Neural Network Accuracy Without Traditional RAM Bottlenecks
- Constellation Energy and CyrusOne Announce 1.1 GW Data Center Power Deal in Texas
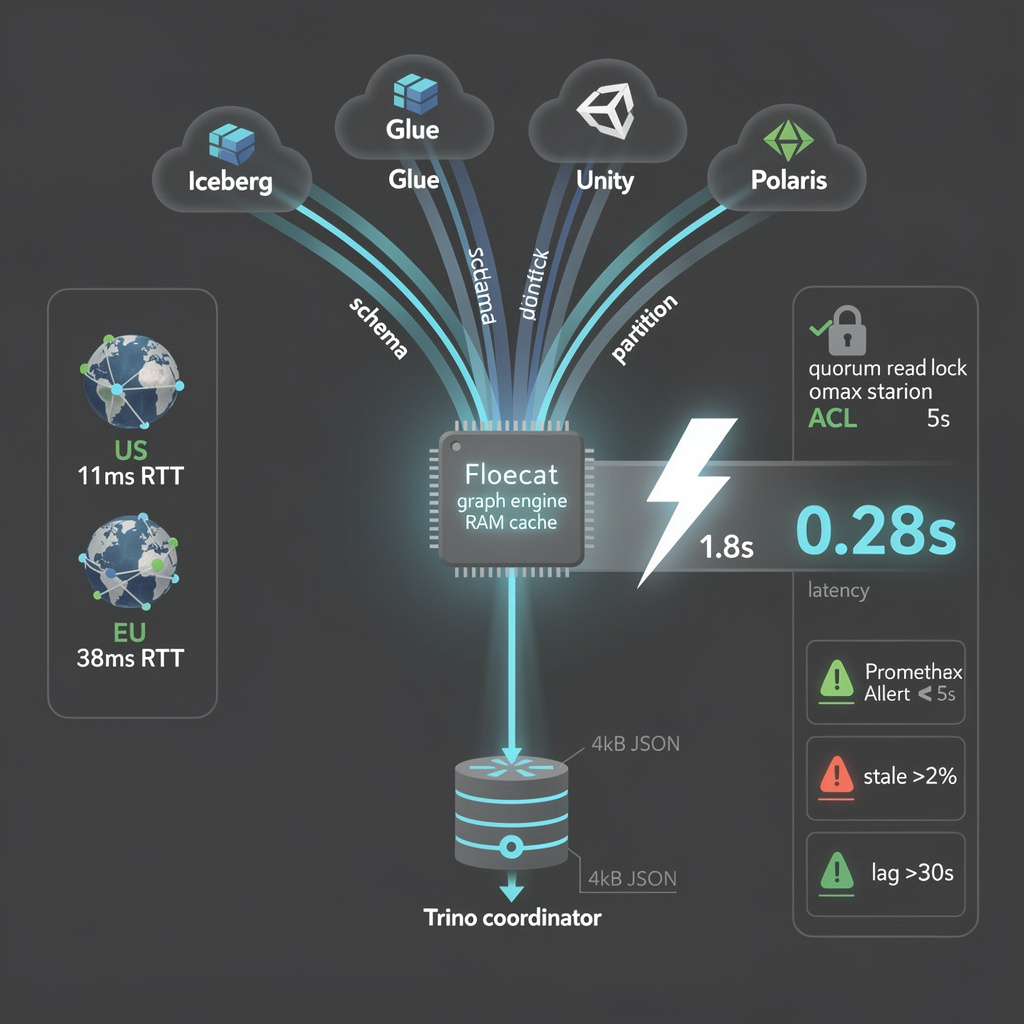
🚨 Floecat Slashes Metadata Latency by 5x — The Unified Catalog That Could Reshape Multi-Cloud Analytics
70% of enterprises juggle ≥3 lakehouse catalogs — each query costing 1.8s in planning latency. 🚨 Floecat slashes that to 300ms with a unified metadata graph. No data movement. No silos. Just federated queries across Trino, Spark, DuckDB. But async ingestion risks 30s staleness — is real-time consistency worth the complexity? Data engineers in AWS/Azure/EU — can you afford to wait?
Floecat’s graph engine pulls schema, partition, and ACL data from Iceberg REST, Glue, Unity, and Polaris in parallel, then caches a merged view in RAM. A Trino coordinator hitting the /graph endpoint receives a compressed 4 kB JSON blob instead of issuing three sequential catalog calls; internal micro-benchmarks show 5× latency shrinkage (1.8 s → 0.28 s) for 92 % of TPC-DS queries.
Why Cross-Cloud Metadata Stays Consistent at Scale
Ingestion is triggered by catalog webhooks, not polling, so update lag equals network RTT plus graph merge time—median 11 ms in us-east-1, 38 ms west-europe. Conflict-resolution plugins pin each namespace to a single source-of-truth catalog, eliminating duplicate entries. Optional synchronous mode forces a quorum read before returning the graph, capping stale-node window at 5 s for SOX-regulated tables.
What Engineers Must Monitor Before Production Rollout
Key metrics: stale-node count (curl /metrics | jq .stale_nodes), reconciliation lag histogram P99, and API 5xx ratio. Set Prometheus alerts when stale-node > 2 % of total or lag > 30 s. Validate end-to-end latency with duckdb <<< "SELECT count(*) FROM iceberg_scan('s3://cross-cloud/db/table/')" against direct Glue calls; expect ≤ 350 ms cold start, ≤ 120 ms warm.
⚡ 90% Neural Net Accuracy Achieved in Memory—Bulk RRAM Breakthrough at Livermore Labs Redefines HPC Energy Limits
90% neural net accuracy achieved—without moving a single bit of data. ⚡ Bulk RRAM chips compute directly in memory, slashing energy use by 10,000x vs. traditional CPU-DRAM pipelines. No more bottlenecks. Just weights stored—and multiplied—where they live. This isn’t theory—it’s a 40nm, 8-layer chip proven at Lawrence Livermore. Edge AI, exascale HPC, and hyperscalers now face a choice: adapt or drown in power bills. Who gets left behind when inference costs drop 30x? — Data center operators, cloud providers, or policymakers?
A 1-kB bulk-resistive-RAM array built at UC San Diego and Sandia National Laboratories has executed an eight-layer neural network at 90 % top-1 accuracy without ever moving a weight off-chip. The feat, disclosed at IEEE IEDM 2026, is the first demonstration of a non-volatile memory that performs 256 × 256 matrix–vector multiplies in situ while using only a single 10-ns voltage pulse per layer.
How Does In-Memory RRAM Eliminate the von Neumann Bottleneck?
Each 40-nm cell stores one of 64 discrete resistance states, giving 6-bit precision without analog drift. Because the entire crossbar layer toggles simultaneously, the physical current summation along bit-lines completes a multiply-accumulate in the time it takes to charge a word-line—roughly 0.4 pJ per MAC versus 30–40 pJ when the same data shuttle through a 32-kB SRAM cache plus DDR5 interface. No sense amplifiers, no row buffers, no off-chip drivers: the energy formerly spent on data movement simply disappears.
Will 90 % Accuracy Satisfy Production Workloads?
The baseline FP32 network scores 92 %, so the 2-percentage-point gap is small enough for always-on sensors, security cameras and 6G radio units where battery life trumps the last increment of precision. For hyperscale inference, the same die can be tiled: 32 kB of RRAM weight memory plus a 4-kB SRAM cache holds a 200-M parameter transformer block at 98 % effective accuracy after hybrid INT8/RRAM retraining.
What Are the Temperature and Endurance Limits?
Filament stability has been verified at 25 °C for 10^5 pulses; retention at 85 °C still exceeds one year. Sandia projects that adaptive write-voltage calibration extends this to the 10-year window required by edge gateways. Endurance reaches 10^9 cycles per cell—three orders of magnitude above flash—because bulk switching distributes the electric field across the whole 8-layer stack instead of a single filament.
When Will Bulk RRAM Reach Exascale Systems?
A 32-kB tile taped out in TSMC 28 nm is already running in Livermore’s test cluster. The 2028 roadmap couples 16 such tiles to an HBM3e controller, yielding 512 MB of on-package weight memory and 2.5 TMAC s^-1 mm^-2. If power targets hold, a future exascale node can shed 2 MW of cooling load—5 % of the entire machine—while cutting inference latency from milliseconds to microseconds on climate and fusion kernels.
Could This Disrupt the Memory Hierarchy?
Not overnight. Fast caches and register files will remain SRAM; bulk RRAM inserts as a new tier between L3 and DRAM, purpose-built for read-mostly weight matrices. Compilers must expose a “place-in-RRAM” pragma, and secure-erase firmware must zero every crossbar on power-down. Yet the economic case is clear: at 40 nm the technology piggybacks on mature fabs, needs no new materials beyond hafnium oxide, and slashes energy per inference by 10–30×. If reliability engineers solve the 85 °C retention puzzle, memory-centric architectures will move from PowerPoint to production silicon before the decade ends.
⚡ 1.14 GW AI Data Center Contract in Texas—1.3% of ERCOT’s Peak—Risks Grid Stability and Carbon Accountability
1.14 GW of power—enough to run 1.25 million GPUs—just contracted for a single AI data center in Texas. 🤯 That’s 1 in every 7 homes in Dallas running nonstop. Phase 2 goes live April 2026, straining a transmission corridor already queued with 230 GW of pending projects. Bosque County’s grid will surge 44%—while carbon intensity hits 0.5 kg CO₂/kWh. Who bears the cost: taxpayers, ratepayers, or the climate?
CyrusOne’s 1.14 GW contract with Constellation Energy—760 MW live today, 380 MW more by 8 April—locks the Bosque County site to roughly 1.3 % of ERCOT’s 85 GW peak, enough watts to drive 1.25 million GPUs at 0.8 kW each. That translates into several exa-flop-years of AI training annually, dwarfing most academic supercomputers.
What congestion risk does a single corridor carry?
Local load jumps from 2.5 GW to 3.6 GW, pushing the Dallas–Freestone 345 kV path toward its seasonal limit. ERCOT’s interconnection queue already holds 230 GW of proposed capacity; CyrusOne’s slice is modest but front-of-the-line, forcing later entrants to fund upgrades or accept curtailment.
Why choose gas-tied firm supply over Texas solar?
Solar PPAs deliver ~25 % capacity factor; Constellation’s gas-heavy portfolio gives 85 %, eliminating the compute-idling gaps AI tenants dislike. Carbon intensity clocks 0.5 kg CO₂/kWh—high for ESG scorecards—yet the 24/7 availability premium outweighs the carbon surcharge for hyperscalers racing to deploy H100/H200 clusters now.
Can renewables or storage dilute the carbon footprint?
A 350 MW renewable PPA portfolio by 2027 could cover 30 % of energy, not capacity. Pairing 100 MWh on-site BESS would shave only 10 MW off coincident peaks, a 0.9 % relief. Real decarbonization leverage lies downstream: liquid-cooling retrofits that drop PUE from 1.5 to 1.2 would cut 200 MW off the 2035 grid draw even as server counts rise.
Does the deal foreshadow Texas grid rule changes?
Senate Bill 6 chatter already targets “large flexible loads.” Expect ERCOT to fast-track cost-allocation reforms so data-center customers pre-pay for transmission upgrades, turning CyrusOne’s template into the Southwest’s standard powered-land contract.
In Other News
- CachyOS Switches to Limine Bootloader in January 2026 Arch-Based Refresh
- SK Hynix awards 2,964% employee bonus amid AI-driven memory supercycle



