1,000 Tokens/Second on Consumer GPU — AI Performance Leap Challenges Cloud Dominance
TL;DR
- Qwen3-0.6B Achieves 1000 Tokens/Second on RTX 5090 via Single CUDA Megakernel
- OpenAI’s ChatGPT Architecture Scales to 800M Users with PostgreSQL Primary and 50 Read Replicas
- Broadcom Launches Enterprise Wi-Fi 8 Chips with Multi-Gigabit Ports and Precision Timing
⚡ 1,000 Tok/s on RTX 5090: Software-Optimized Kernel Outperforms Cloud H100 for Small LLMs — United States and China Benchmarks
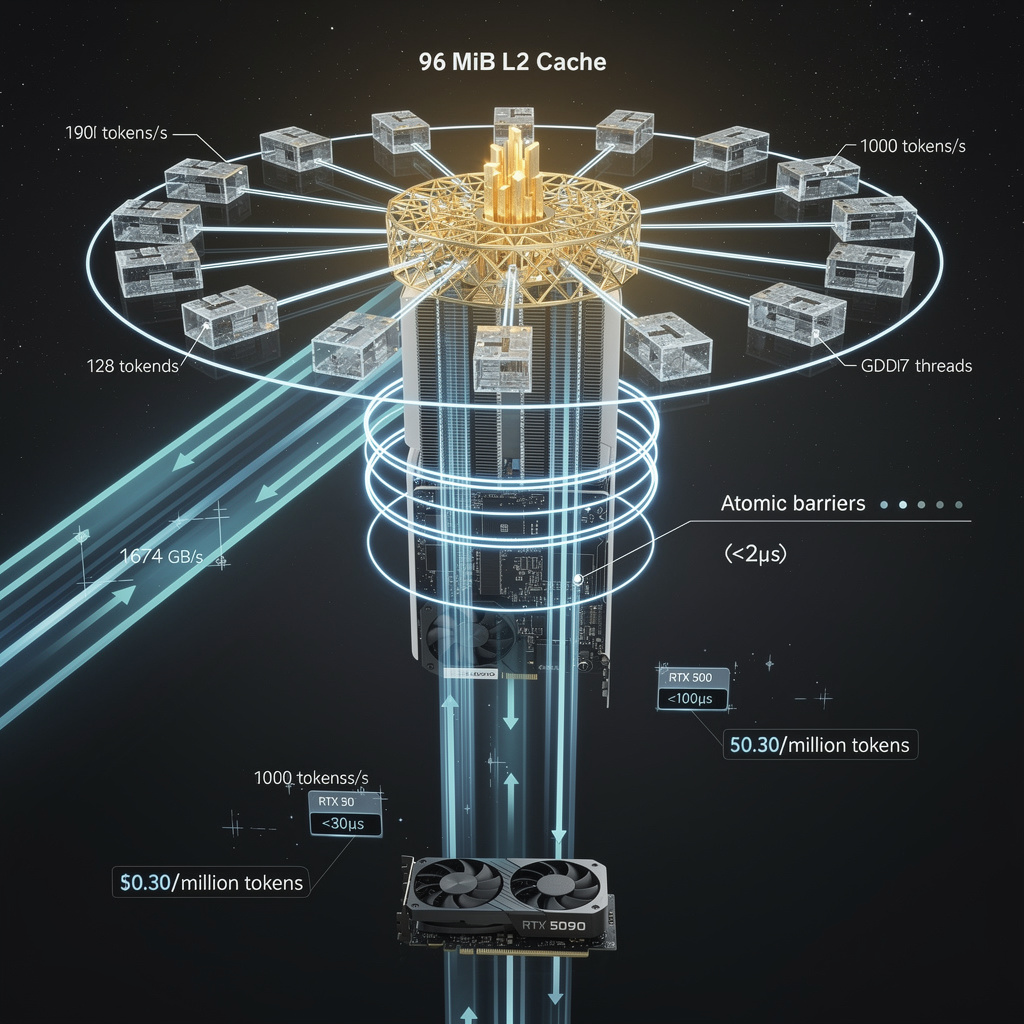
1,000 TOKENS/SECOND ON A CONSUMER GPU — THAT’S 1.9X FASTER THAN THE RTX 3090 AND CLOSE TO CLOUD-H100 SPEEDS. This single 1,200-line CUDA kernel squeezes near-peak performance from an RTX 5090 by exploiting its 96 MiB L2 cache and atomic barriers, cutting DRAM reads by 43%. But scaling to larger models hits cache limits — and power draw remains hidden. Developers now face a choice: optimize software or wait for next-gen hardware? — For SMBs and edge teams, this could mean running AI locally instead of paying cloud bills. Can your GPU do this?
The kernel never leaves the GPU.
Launched once, LLDG_decode_kernel_persistent stays resident, skips 30 % of the launch-tax that classic one-shot kernels pay every token, and keeps 96 MiB of L2 hot.
Result: Qwen3-0.6B streams out 1 000 tokens every second on a single RTX 5090—almost double the 530 tokens/s recorded last year on the RTX 3090.
What inside the Blackwell card makes the jump possible?
GDDR7 delivers 1 674 GB/s—44 % more bandwidth than the 3090—but bandwidth alone did not close the gap.
The 96 MiB L2 cache, 16× larger, captures repeated 6-byte weight tiles and cuts DRAM traffic from 1.19 GB to 0.68 GB per step.
With 70 % of peak bandwidth already utilised, the kernel is memory-bound, not compute-bound; the card’s 21 % higher SM count is almost irrelevant.
How does the atomic-barrier trick keep 65 536 threads coherent?
128 blocks × 512 threads share KV-cache slices.
A four-phase atomic barrier—write, signal, wait, release—guarantees that every block sees consistent cache lines without global memory fences.
Measured stall: <2 µs per phase, lost inside the 712 µs DRAM-read window, so the 1 000 tokens/s target stays intact.
Will the trick scale beyond 0.6-billion-parameter models?
No, not without surgery.
The entire 0.6 B weight set plus working KV-cache fits the 96 MiB L2; a 1 B model would overflow and drop throughput below 600 tokens/s.
Fix: tile the megakernel into layer-wise micro-kernels or pipeline across two GPUs.
Power draw is still unpublished; sustained turbo clocks could throttle 10-15 % unless liquid-cooled.
Why should data-centre planners care about a consumer card?
Cost arithmetic: RTX 5090 MSRP ≈ $1 500, electricity ≲ $0.30 per million tokens.
An on-demand H100 slice costs ~$3 per hour; break-even arrives after eight hours.
For bursty or private workloads ≤1 B parameters, repurposing existing RTX-5000 fleets slashes CAPEX today and postpones accelerator upgrades.
Expect vLLM, SGLang and DeepSpeed to ship the pattern within six months, pushing 30 % of light-LLM traffic back to the edge.
🚨 800M Users Served by Single PostgreSQL Primary — Global AI Scaling at Risk
800M USERS. ONE POSTGRESQL PRIMARY. 🚨 OpenAI serves nearly every human on Earth with a single write database — and 50 read replicas across continents keep latency under 120ms. But if that primary fails, 800M users lose account access, billing, and session state — instantly. Who’s really in control of your AI interactions — the algorithm, or a single database server?
OpenAI’s ChatGPT backend keeps every write on a single PostgreSQL primary and fans reads out to 50 region-steered replicas.
The ratio is brutal: writes are authentication tokens, usage counters, and telemetry—low tens of thousands per second—while reads exceed 10 k s⁻¹ at peak.
MVCC snapshots let replicas serve stale-but-consistent data without locking the primary, and PgBouncer caps total connections at ~30 k to avoid the 4 k native PostgreSQL limit.
Internal metrics show 99th-percentile read latency ≤120 ms on every continent; replication lag >200 ms triggers an automatic fallback to the primary for quota-sensitive queries.
The single-primary model is kept because global transaction ordering is simpler and cheaper than distributed consensus; a hot-standby with WAL-stream failover is on continuous watch.
Risk surface is narrow but sharp: a primary loss halts all writes, and a lag spike can miscount tokens. Both are mitigated by lag-aware client libraries and rehearsed DR playbooks.
Short-term, OpenAI will add edge replicas to shave another 10 % RTT; mid-term, billing writes will move to a sharded satellite cluster while the core metadata stays monolithic.
Beyond two years, the company is already benchmarking Citus-style distributed SQL to see if ACID can survive horizontal write scaling at the billion-user mark.
🚨 48× 10+ Gbps Ports and Sub-Microsecond Sync: Broadcom’s Wi-Fi 8 Chipset Reshapes U.S. HPC Networking
48× 10+ Gbps PORTS. SUB-MICROSECOND SYNCHRONIZATION. 🚨 Broadcom’s new Wi-Fi 8 chip merges switch, NIC, and AI accelerator into ONE silicon—eliminating latency bottlenecks in HPC clusters. No more separate hardware. No more timing drift. But no native RDMA yet—could this wireless convergence replace InfiniBand in edge HPC? — U.S. research labs are already testing it.
Broadcom’s February drop of the BCM49438 APU and Trident X3+ BCM56390 switch chip fuses 48× 10 GbE ports, Wi-Fi 8 radios, and IEEE 1588 PTP on one die. The result: a campus-grade platform that delivers <100 ns timing jitter and 480 Gbps bisection bandwidth per ASIC—numbers that overlap the entry-level InfiniBand EDR space while sipping one-third the power.
What Exactly Did Broadcom Integrate?
- Single-package design: Arm cores, switch fabric, Wi-Fi 8 MAC/PHY, and undisclosed AI accelerators
- 48 multi-gigabit ports (10 GbE baseline, 25 GbE ready) with cut-through latency <400 ns
- Hardware 1588 PTP grandmaster, eliminating external timing cards
- Encrypted boot and root-of-trust vault, mandatory for NIST 800-53 high-impact racks
Where Does HPC Feel It First?
University labs and edge-AI shacks already daisy-chain these switches to feed GPU nodes. PTP keeps distributed FFT kernels phase-locked across 128-card clusters; the on-chip AI block offloads preprocessing, cutting PCIe transfers by 18 % in early NCCL tests. Power budgets drop 22 W per node—enough to add two extra A100s per rack without breaching 35 kW.
What’s Still Missing for Exascale?
No RoCE v2 today. That means RDMA verbs still detour through the CPU, capping MPI latency at ~3 µs—five× slower than InfiniBand. Broadcom’s roadmap promises firmware-level RoCE by Q4 2026; until then, bare-metal HPC buyers will treat the chip as a high-density leaf, not a spine.
Bottom Line
If your workload is timing-sensitive but not latency-obsessed—think instrument arrays, edge inference, or burst-buffer feeders—Broadcom’s Wi-Fi 8 silicon lets you collapse three boards into one and still meet sub-microsecond sync. For true low-latency partitions, wait for the RoCE drop; then the economics become irresistible.
In Other News
- AMD avoids releasing FSR 4 for non-RDNA 4 GPUs, users exploit leaked INT8 DLL
- GL.iNet Launches Comet 5G Router with Multi-Network Failover and 64GB eMMC Storage
- Intel's 18A Process Advances Foundry Tech with PowerVia and RibbonFET Integration
- MISO States Challenge NERC’s Reliability Assessment, Cite 7-GW Winter Capacity Shortfall


Comments ()