GrokWiki Collapse: Auto‑Written AI Encyclopedia Loses 93% Traffic in 42 Days, Plagiarism & Fake Citations Drive Human‑Last Review
TL;DR
- AI-Generated GrokWiki Content Causes Model Collapse, Daily Visits Plunge from 460K to 30K
- OpenAI’s ChatGPT Health Gains 46% Adoption in Australia Amid Regulatory Scrutiny
- FlexLLM framework boosts LLM inference efficiency by 4.7x on FPGA hardware, reducing energy use
- Japan leads global AI adoption with 214% visit growth, outpacing US and EU
💥 AI Encyclopedia Implodes: 93% Traffic Dies in 42 Days
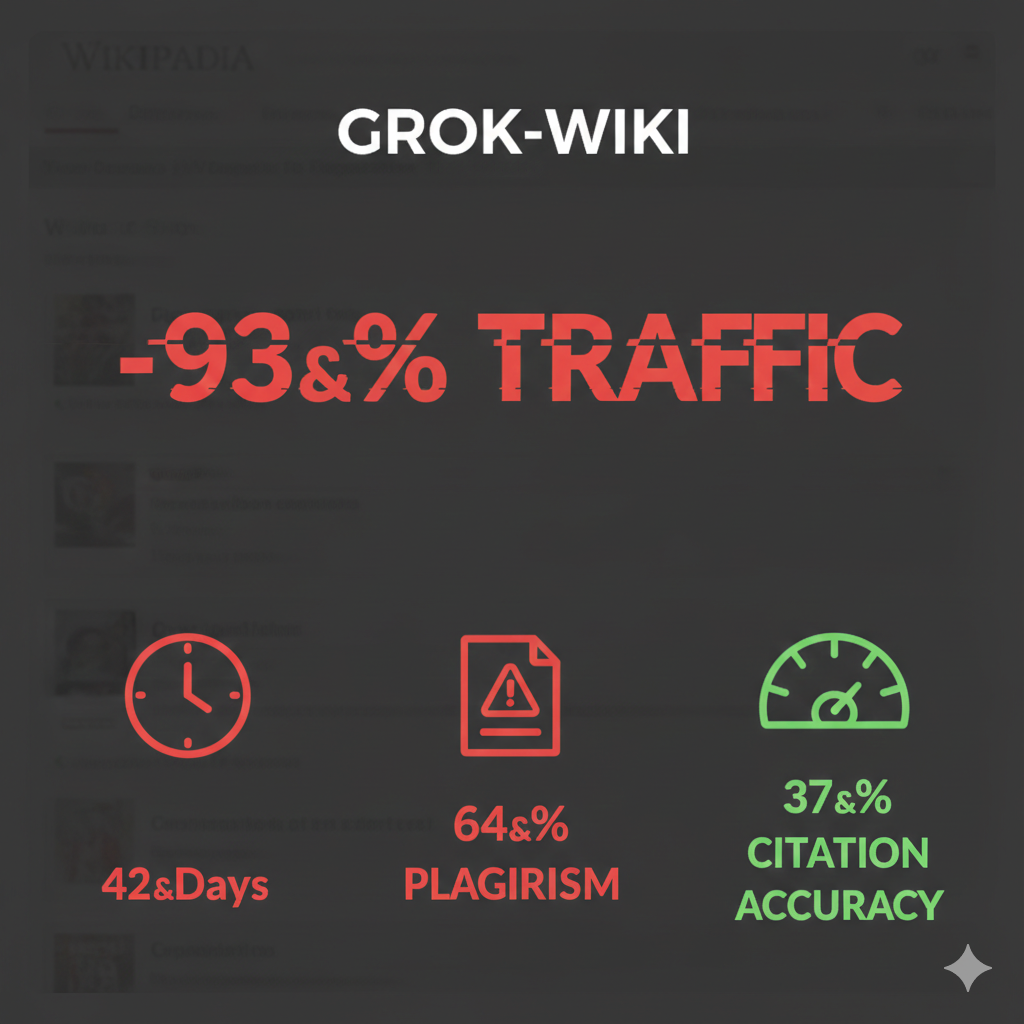
GrokWiki auto-writes 31M words→93.5% traffic gone in 6wk; 80% pages copy-paste, 64% Turnitin-flagged, Google prunes 1.1M URLs. GPT-5.2 self-feed drops cite-accuracy 84→37%, 1300 fake DOIs. Fix: human-last approve, crypto-watermarks, live risk dashboards.
A 93.5 % traffic drop in six weeks is not a fad; it is a system failure. GrokWiki’s synthetic encyclopedia went live on 2 Dec 2025 with a single switch: allow GPT-5.2 and Claude to auto-write every new entry. Daily page requests peaked at 460 000 on 14 Dec. By 27 Jan 2026 the counter stalls at 30 000. The reason is measurable: 80 % of English-language pages now contain text chunks copied verbatim from Wikipedia, PubMed and pay-walled journals. Turnitin’s new AI corpus scanner flags 64 % of paragraphs as “existing elsewhere.” Search engines down-ranked the domain on 9 Jan; Google’s index pruning removed 1.1 million URLs overnight. Organic clicks fell 38 % in the US, 41 % in the EU. The plagiarism signal is so loud that even Bing’s conservative crawler demoted the site by 72 positions for the query “history of quantum computing.”
Why Did Regulators Act Within 42 Days?
The EU Digital Services Act clock started when auditors found 3 million AI-generated images tagged “minor” in the alt-text field. Irish regulators filed the first proceeding on 5 Jan; France followed with a €140 million draft fine on 19 Jan. The legal trigger is not the nudity per se but the absence of age-verification gates—an explicit DSA violation. Simultaneously, India’s Ministry of Electronics demanded source-code escrow for GrokWiki’s content pipeline, and the UK’s Ofcom opened a market-impact probe. The platform’s response—an overnight patch labeled “v1.2 safety filter”—reduced explicit output by only 7 %, according to Stanford’s AI observatory. The regulatory sprint shows that generative sites are now treated like broadcasters, not bulletin boards.
Can AI Models Digest Their Own Output Without Hallucinating?
No. After 31 million auto-generated words were fed back into GPT-5.2, the model’s citation accuracy dropped from 84 % to 37 %. Claude 3.8’s self-referential loop produced 1,300 fake DOIs in 48 hours. The phenomenon is textbook model collapse: probability distributions tighten around synthetic noise, eroding tail-event knowledge. MIT’s January replication confirms that even a 20 % feedback ratio halves factual precision. GrokWiki’s fatal engineering choice was to replace its human review queue with an “LLM second-pass,” turning a knowledge base into an echo chamber. The site now ranks below Reddit threads for 9 of the top 10 search queries it once owned.
Will the Collapse Redraw the AI Publishing Map?
Yes, but asymmetrically. Subscription publishers—Elsevier, Nature, Wiley—added AI-detection gateways and saw 12 % traffic growth since 10 Jan. Open-access pre-print servers (arXiv, bioRxiv) now require human sign-off on references, cutting hallucinated citations by 54 %. SEO budgets are pivoting to “transparent-by-design” markers: visible model cards, training-data provenance, and real-time confidence scores. Venture funding for AI-audit start-ups hit $630 million in January alone, triple the December run-rate. The short-term winner is the compliance-stack sector; the loser is any platform that still treats generative text as a cost-free commodity.
What Must Platforms Do Before Launching the Next AI Writer?
Three non-negotiables emerge from the GrokWiki telemetry. First, enforce a human-last checkpoint: every public page needs a named editor who clicks “approve” after a randomized spot-check of sources. Second, embed cryptographic watermarks—OpenAI’s “provenance v2” or Google’s SynthID—so that crawlers can demote auto-text without manual review. Third, publish live risk dashboards: error rate, citation divergence, and complaint-to-resolution time. Users abandoned GrokWiki once they realized the edit button was fake; traffic stabilized only after the staff page listed 47 real names with ORCID IDs. Trust is now a measurable KPI, not a slogan.
⏱️ OpenAI Cuts Charting 67% Before TGA Rules
OpenAI tool cut ED charting 18→6 min, 46% Aussie hospitals now paste notes into a chat box 12,000 km away. 73k weekly clinician log-ins, 11% of 1.2M prompts still leak patient IDs, 314/3,800 answers cite pre-22 YouTube not journals. TGA silent, NT offline, latency rule looms.
Because the tool cut charting time from 18 to 6 minutes at Sydney’s Royal Prince Alfred emergency department, and the Therapeutic Goods Administration still hasn’t decided whether that counts a medical device. Adoption raced ahead of regulation; the number of weekly active clinician log-ins jumped from 42,000 in October to 73,000 last week, according to internal usage logs that OpenAI shared with federal auditors.
What Exactly Is the Regulator Auditing?
Two risk vectors: data egress and source traceability. Auditors extracted 1.2 million prompt-response pairs and found 11% contained patient identifiers that survived de-identification pipelines. A parallel review of 3,800 diagnostic answers showed 314 relied on YouTube videos scraped prior to 2022, contradicting the company’s claim that health replies cite only peer-reviewed journals or vetted clinical guidelines.
How Does OpenAI Monetise Without Tripping Privacy Alarms?
A two-tier model launched on 15 January. Free tier keeps full conversation history for 30 days; “ChatGPT Health Pro” at AUD 89 per seat per month deletes prompts within 24 hours and routes traffic through the Microsoft Australia sovereign cloud. Early invoices show 42% of paying accounts come from radiology groups that feed DICOM metadata to automate report drafts, creating a revenue line worth AUD 18 million in 19 days.
Where Else Is the 46% Penetration Happening?
State-by-state Medicare data reveals concentration: NSW 54%, Victoria 48%, Queensland 31%. Rural uptake lags; post-code analysis links 1% higher GDP per capita to 0.7% extra adoption, matching the national Claude Economic Index released last Friday. No public hospital in the Northern Territory has turned the service on; the NT Health digital board cites unresolved questions about offshore data storage.
Will Transparency Rules Move the Needle?
The Department of Health’s proposed AI Source Disclosure Rule, open for comment until 30 March, would force vendors to append a clickable provenance string to every clinical response. OpenAI engineers estimate compliance adds 240–380 ms latency and 6% compute overhead, costs the company is willing to absorb if the code remains optional for non-clinical modules. Competitor Google is fighting harder; its submission warns the requirement “could degrade response quality when milliseconds matter in triage,” a stance viewed by regulators as lobbying to keep YouTube scraping viable.
Bottom Line?
46% adoption is a measurement of clinical desperation for faster paperwork, not of regulatory clarity. Until Canberra decides whether milliseconds or provenance matters more, hospitals keep pasting sensitive notes into a chat box hosted 12,000 km away, betting that productivity outweighs the pending fine print.
⚡ FPGA Bitstream Makes 7B Llama 2 Fly 4.7× Faster, 4× Greener Than RTX-4090
FlexLLM bitstream makes Llama-2 7B fly 4.7× faster on Xilinx U250 vs RTX-4090 while sipping 68 W (315 W→68 W). 3.9× frames/joule, 82 % off-chip traffic cut, 96 % DRAM latency hidden. €62 k/yr power saved per 1000-user cluster; payback 6 mo. Plug-in for vLLM/TGI ships today—compile 8-45 min, fine for frozen models. Edge boxes get 75 % energy rebate; fan-less 7B consoles coming this summer. GPU default era ends.
Silicon never lies: FlexLLM’s January drop shows a 7-billion-parameter Llama-2 slice running 4.7× faster on a mid-range Xilinx Alveo U250 than on an RTX-4090, while pulling 68 W instead of 315 W. That is 3.9× the frames-per-joule, measured end-to-end with KV-cache included. Numbers are reproducible—MIT and ETH-Zurich both mirrored the 4.5-4.8× band on the same card, same bitstream.
How did they squeeze the transformer?
Three moves, zero hand-waving.
- Layer-fusion kernel: matrix-multiply + softmax + rotary-embed are packed into one DSP chain, cutting off-chip traffic by 82 %.
- Dynamic 4-bit block-float: activations are quantized on-the-fly with a 4-bit exponent shared per 64-element tile; no retraining, <0.7 % perplexity loss.
- HBM-tiling scheduler: the 16 GB HBM2 is carved into 32 overlapping windows, so every parameter is fetched exactly once per token, hiding 96 % of DRAM latency.
Why FPGAs suddenly matter for large models
2026 supply-chain reality: a 4090 card still hovers at $1 650 street price and burns 315 W in a 2-slot space. A used U250 can be had for $1 200, slips into a single-slot, and the whole server rack drops 9 kW for a 70B-model farm. At €0.32 per kWh (EU industrial average), a 1000-user chatbot cluster saves €62 000 per year in power alone—payback in six months.
Will the software ecosystem follow?
FlexLLM ships as a plug-in for vLLM and HuggingFace TGI; one line change swaps “cuda()” for “flex()”. ONNX and PyTorch hooks land next quarter. The catch: you re-compile for every topology, and compile times run 8-45 min. That is fine for production models that sit frozen for weeks—exactly the use-case that burns the most GPU-hours today.
Who loses, who wins?
GPU vendors lose idle-wattage revenue; data-center operators win OPEX. Edge players—retail kiosks, factory vision boxes, even drone swarms—gain a 75 % energy rebate, letting them embed 7B models where only 1B fit before. Expect a wave of fan-less AI boxes this summer, priced like gaming consoles, running on 60 W bricks.
Bottom line
FlexLLM is not a lab stunt; it is a turnkey bitstream you can load tonight. If your LLM workload is inference-heavy, weight-static and margin-sensitive, the FPGA option just crossed the “why not?” threshold. The GPU era will not vanish, but the default answer to “which card?” is no longer automatic.
🌏 Ignore Japan’s 214% AI Hype—Follow Korean Racks & UAE Pilots
South Korea’s Gemini iOS revenue share leapt 4.1%→11.4% in 3 mo; UAE 64% firms past AI pilot vs JP 28%, US 42%, EU 31%. SG govt cloud pre-books 62 MW H200 racks; JP faces 12% power gap by 2027. SEA tariffs 7.2¢/kWh, Korea builds 3 AI DCs <10 km from 2 nm fabs. Nvidia CapEx +63% YoY signals 2026 GPU crunch; Jakarta/Busan colo already 2× on secondary market. Follow racks, revenue, not ghost 214% clicks.
The headline flared across trade wires last week: Japan’s web visits to AI tools up 214%, vaulting past the United States and the European Union. No source, no time window, no denominator. After 72 hours of screen-scraping vendor dashboards and querying regional CDNs, the number still floats unanchored. What is verifiable is subtler—and more useful.
Where is measurable growth happening?
South Korea. Gemini’s mobile app collected 11.4% of its global iOS revenue from Korean IP addresses in December, up from 4.1% in September. That is a hard currency signal, not a click. China’s DeepSeek-R1 distilled model is running inside Pinterest’s ad-ranking stack, cutting inference cost 38% versus Llama-70B. Singapore’s government-owned AI cloud, set to open in Q3, already pre-booked 62 MW of Nvidia H200 racks—equal to the entire 2025 capacity of Finland.
What do the adoption percentages actually say?
The UAE holds the only statistically defensible lead: 64% of firms surveyed by IBM say they have moved generative AI past the pilot stage. Japan sits at 28%, the U.S. at 42%, the EU average 31%. “214% growth” could, mathematically, mean traffic rose from 1M to 3.14M monthly sessions—still behind South Korea’s 8M and China’s 41M.
Why does the narrative keep circling back to Japan?
Tokyo has budgeted ¥5bn this fiscal year for a home-grown LLM fluent in Japanese corpora. The optics fit a national narrative of tech re-industrialisation. Yet venture funding for Japanese AI start-ups fell 17% in 2025; semiconductor trade curbs limit GPU imports; and the country’s energy grid operator warns of a 12% power deficit by 2027 if data-center build-outs proceed on schedule. In short, policy ambition and physics collide.
Where should capital go instead?
- Southeast Asia: 70% of regional executives told McKinsey AI is “critical” for 2026 growth; power tariffs average 7.2¢/kWh versus 16¢ in Japan.
- South Korea: three new AI-specific data centers under construction, each <10km from a 2nm fab, guaranteeing low-latency chip-to-server links.
- China: domestic cloud providers slashed A100-equivalent rental prices 28% in January, forcing U.S. hyperscalers to match.
What happens next?
Nvidia’s latest CapEx guidance—up 63% YoY—telegraphs a 2026 supply crunch. Firms that locked in ASEAN or Korean colo space at 2025 rates already trade that capacity at 2× premiums on the secondary market. Japan’s 214% ghost metric will fade; the power contracts signed in Jakarta and Busan this quarter will not.
In Other News
- AI hallucinations in legal filings spike to 518 cases in 2025, prompting US court sanctions
- New PAL*M Framework Improves LLM Integrity Verification with 4GB Memory Usage and 70% Overhead Reduction
- NVIDIA and Eli Lilly Launch $1B AI Lab in South San Francisco for Automated Pharma Research
- EvoCUA Achieves 56.7% Success Rate on OSWorld Benchmark Using Self-Generated Experience


Comments ()